ブログに戻る
2分で読めます
ブログ
リサーチ
Mistral Moderation API
2024年11月7日
Mistral AIチーム
安全性は、AIを実用的にする上で重要な役割を果たします。Mistral AIでは、下流の導入(デプロイ)を保護するために、システムレベルのガードレールが不可欠だと考えています。そこで、コンテンツモデレーション用の新しいAPIを公開します。これは、Le Chatのモデレーションサービスを支えているのと同じAPIです。ユーザーの皆さまが、このツールを自分たちの特定のアプリケーションや安全性基準に合わせて活用し、調整できるようにするために提供を開始します。
ここ数か月の間に、業界および研究コミュニティ全体で、新しいLLMベースのモデレーションシステムに対する関心が高まっているのを私たちは目にしてきました。これにより、モデレーションをアプリケーション横断でよりスケーラブルかつ堅牢にすることができます。私たちのモデルは、以下で定義する9つのカテゴリのいずれかに入力テキストを分類するためのLLM分類器です。エンドポイントを2つ提供します。1つは生のテキスト用、もう1つは会話コンテンツ用です。望ましくないコンテンツは、その文脈に非常に固有であるため、会話コンテキスト内での「最後のメッセージ」を分類するようにモデルを訓練しました。詳細は技術ドキュメントをご覧ください。モデルはネイティブに多言語に対応しており、特にアラビア語、中国語、英語、フランス語、ドイツ語、イタリア語、日本語、韓国語、ポルトガル語、ロシア語、スペイン語で訓練されています。
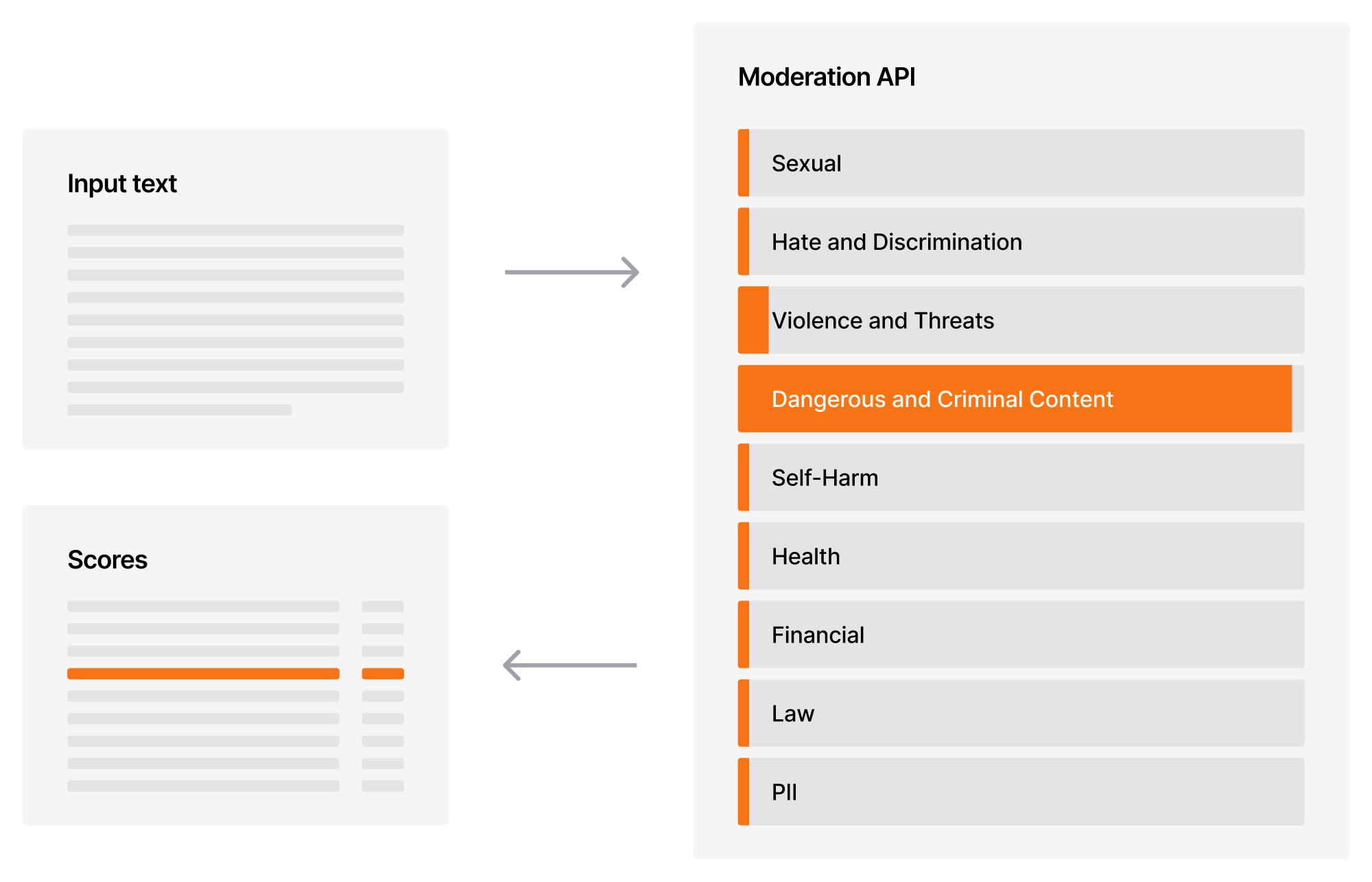
コンテンツモデレーション分類器は、効果的なガードレールのために最も関連性の高いポリシーカテゴリを活用し、資格のない助言やPII(個人を特定できる情報)など、モデルが生成する害への対処によって、LLMの安全性に対する実践的なアプローチを導入します。ポリシー定義の完全なセットと、開始方法の詳細は、 技術ドキュメント で確認できます。
パフォーマンス
以下では、内部テストセットにおけるポリシーごとのAUC PRを共有します。
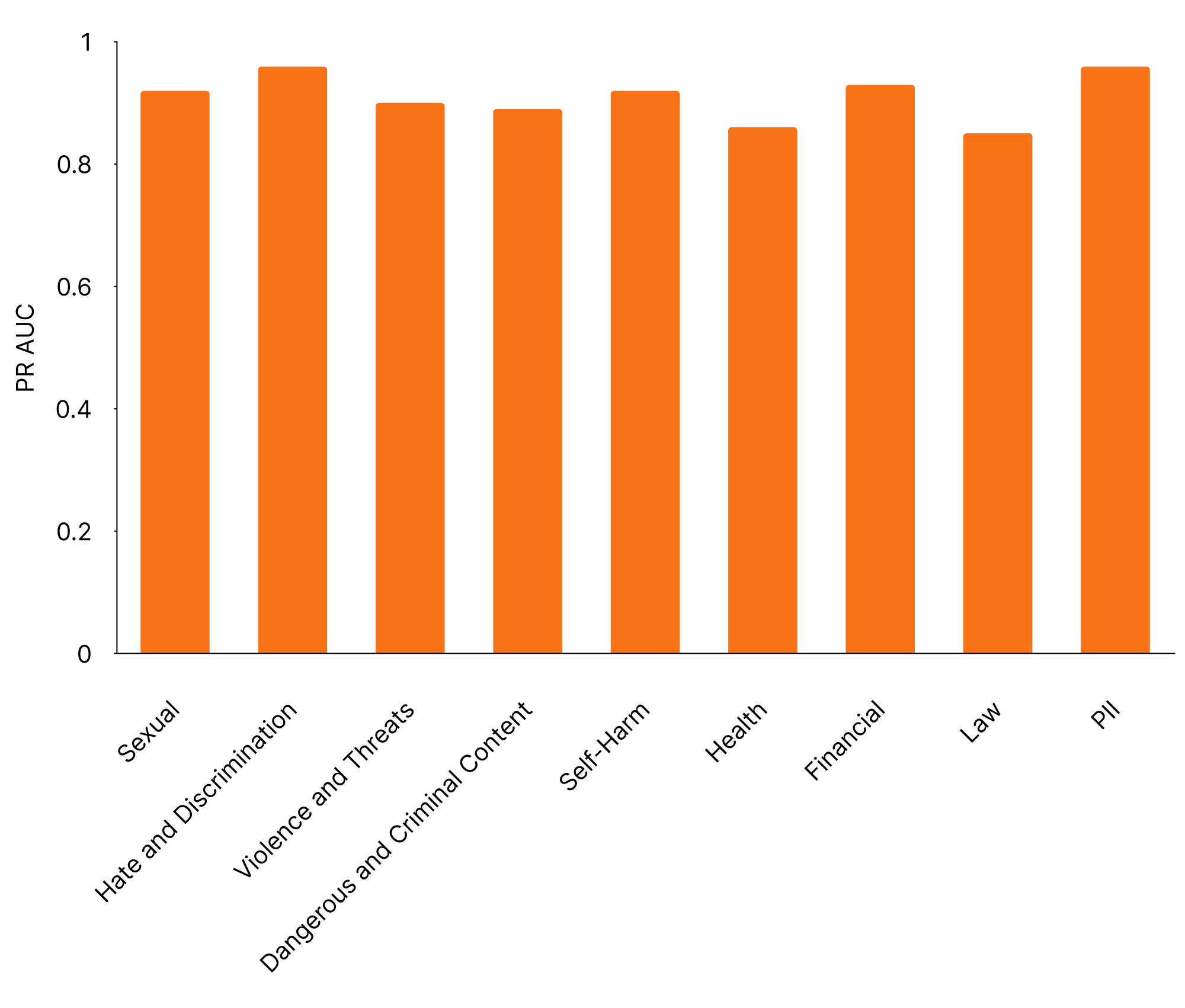
私たちは、顧客と協力して、スケーラブルで軽量、かつカスタマイズ可能なモデレーションのツールを構築し共有していきます。また、研究コミュニティとも連携しながら、安全性の向上に向けた取り組みをより広い分野へ貢献していく所存です。
0%




