
Mistral AIチームは、同サイズとしてはこれまでで最も強力な言語モデルである「Mistral 7B」をリリースできることを誇りに思います。
Mistral 7Bの概要
Mistral 7Bは7.3Bパラメータのモデルで、次の特徴があります:
すべてのベンチマークにおいてLlama 2 13Bを上回ります
多くのベンチマークにおいてLlama 1 34Bを上回ります
コードではCodeLlama 7Bの性能に近づきつつ、英語タスクに対しても良好なままです
高速な推論のためにGrouped-query attention(GQA)を使用します
小さなコストでより長いシーケンスを扱うためにSliding Window Attention(SWA)を使用します
Mistral 7BはApache 2.0ライセンスのもとで提供します。制限なく使用できます。
ダウンロードする そして 当社のリファレンス実装を使って、どこでも(ローカルを含む)利用できます。
vLLMを使って、任意のクラウド(AWS/GCP/Azure)にデプロイします。 推論サーバーとskypilot を利用します。
HuggingFaceで使用します。
Mistral 7Bは、あらゆるタスクに対して簡単にファインチューニングできます。デモとして、チャット向けにファインチューニングしたモデルを提供しており、Llama 2 13Bのチャットよりも上回ります。
詳細な性能
私たちはMistral 7BをLlama 2ファミリーと比較し、公平な比較のためにすべてのモデル評価を自分たちで再実行しました。
ベンチマークはテーマごとに分類されています:
常識推論:Hellaswag、Winogrande、PIQA、SIQA、OpenbookQA、ARC-Easy、ARC-Challenge、CommonsenseQAの0-shot平均。
世界知識:NaturalQuestionsとTriviaQAの5-shot平均。
読解:BoolQとQuACの0-shot平均。
数学:maj@8付きの8-shot GSM8Kの平均と、maj@4付きの4-shot MATHの平均
コード:Humanevalの0-shot平均とMBPPの3-shot
人気の集計結果:MMLU(5-shot)、BBH(3-shot)、およびAGI Eval(3〜5-shot、英語の多肢選択問題のみ)
返却形式: {"translated": "翻訳されたHTML"}

コスト/パフォーマンスの平面においてモデルの良し悪しを比較するために、「等価なモデルサイズ(equivalent model sizes)」を計算する、というのは興味深い指標です。推論・理解・STEM推論(MMLU)において、Mistral 7Bは、それが自身のサイズの3倍を超えるLlama 2と同等の性能を発揮します。これは、メモリの節約とスループットの向上の両方に相当します。
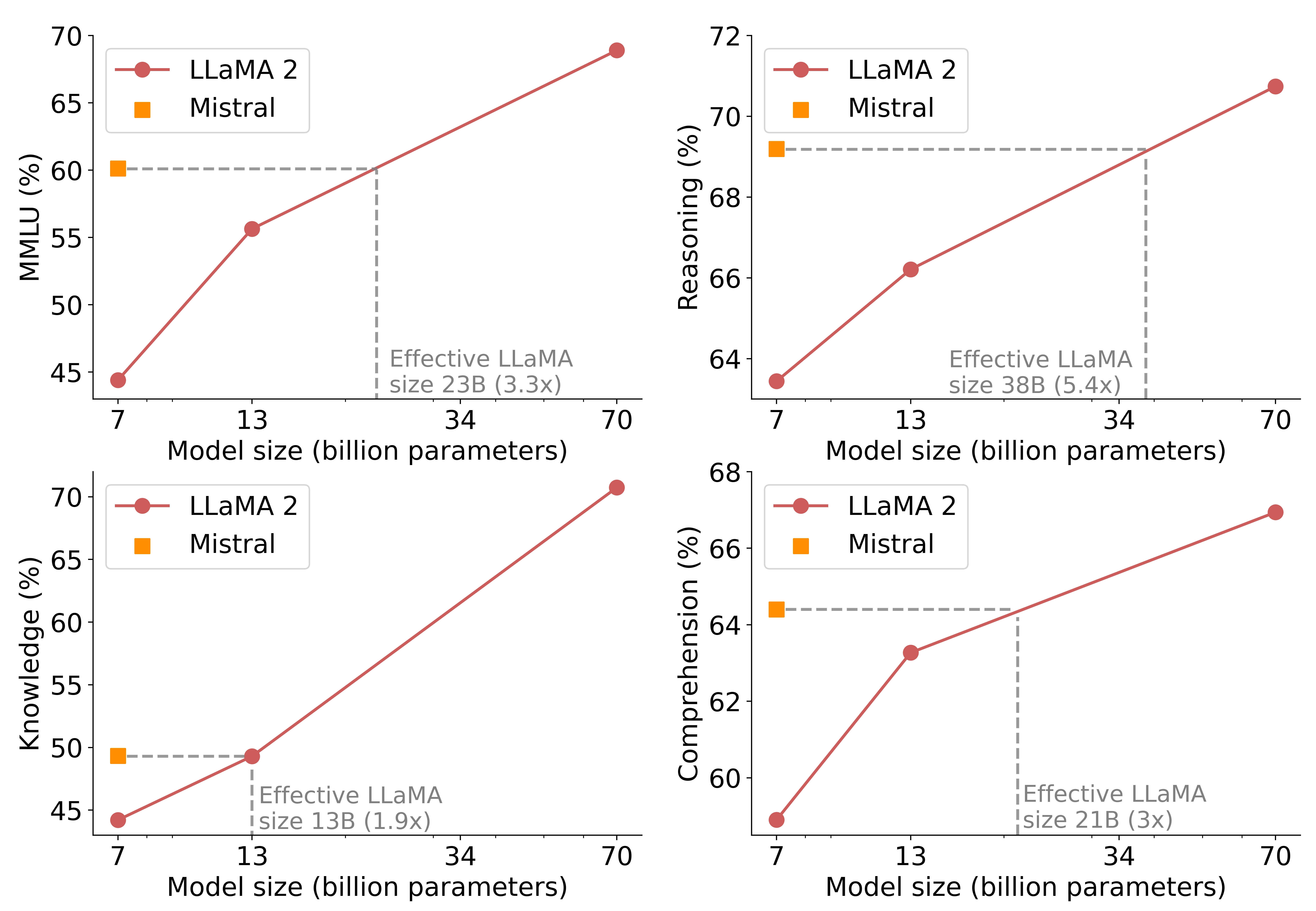
注:当社の評価とLLaMA2論文の間に重要な違いがあります。
MBPPでは、手作業で検証したサブセットを使用します
TriviaQAではWikipediaのコンテキストを提供しません
フラッシュ・アンド・フューリアス:アテンションのドリフト
Mistral 7Bは、スライディングウィンドウ・アテンション(SWA)メカニズム( Child et al. 、 Beltagy et al. )を使用します。この方法では、各層が直前の 4,096 個の隠れ状態に注目します。主な改善点、そして当初これが調査された理由は、計算コストが O(sliding_window.seq_len) に線形であることです。実運用では、 FlashAttention および xFormers に対して行われた変更により、シーケンス長16kでウィンドウを4kに設定した場合に2倍の速度向上が得られます。タイトなスケジュールの中でこれらの変更を取り入れるのを手伝ってくれた Tri Dao と Daniel Haziza に大いに感謝します。
スライディングウィンドウ・アテンションは、トランスフォーマの積み重ねられた層を活用して、アテンションのパターンが示唆するよりも過去のウィンドウ外まで注目します。層 k におけるトークン i は、層 k-1 でトークン [i-sliding_window, i] に注目します。これらのトークンは、トークン [i-2*sliding_window, i] に注目します。より上位の層ほど、アテンションのパターンが想定している以上に過去の情報にアクセスできます。
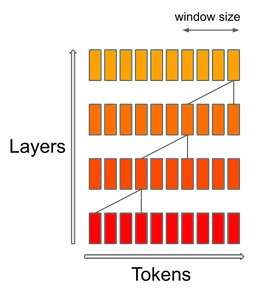
最後に、固定されたアテンションスパンがあることで、キャッシュを sliding_window トークンのサイズに制限できます。回転バッファを使います(詳細は 参照実装リポジトリ をご覧ください)。これにより、シーケンス長 8192 に対する推論ではキャッシュメモリの半分を節約できますが、モデルの品質には影響しません。
チャット向けにMistral 7Bをファインチューニング
Mistral 7Bの汎化能力を示すために、HuggingFaceで公開されている命令データセットでファインチューニングしました。裏技はありません。独自データもありません。その結果得られたモデルである Mistral 7B Instruct は、 MT-Bench で、すべての7Bモデルを上回り、13Bのチャットモデルと同等です。
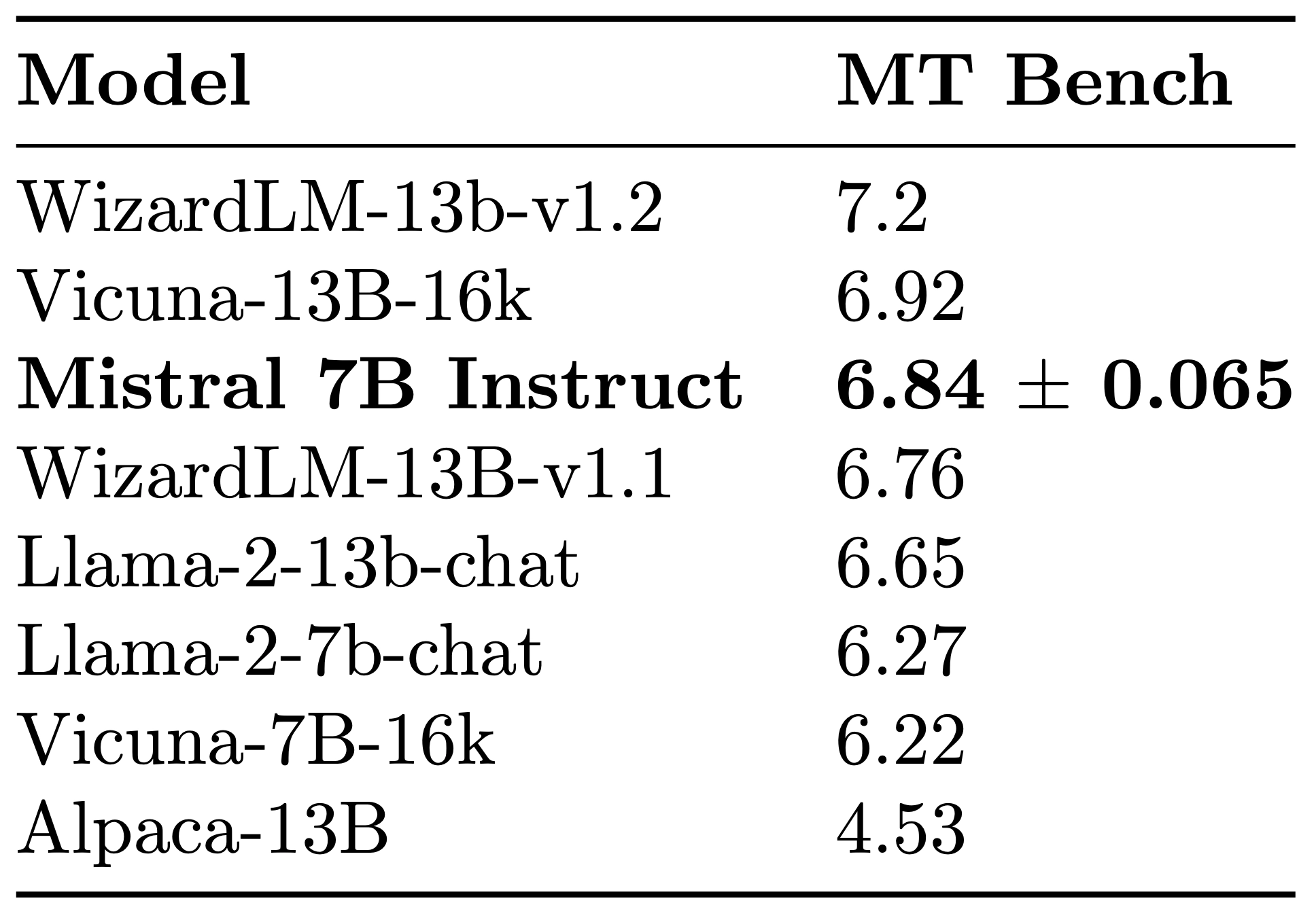
Mistral 7B Instructモデルは、ベースモデルが説得力のある性能を達成するために簡単にファインチューニングできることを素早く示すデモです。モデレーション(不適切コンテンツへの抑制)メカニズムは搭載されていません。ガードレールを細かく尊重する形でモデルを改善し、モデレーションされた出力が求められる環境への展開を可能にする方法について、コミュニティと一緒に取り組むことを楽しみにしています。
謝辞
私たちは、クラスターのとりまとめに24時間体制で支援してくれたCoreWeaveに感謝します。 CINECA/EuroHPC のチーム、そして特にLeonardoの運用担当者に、リソースと支援をいただいたことに感謝します。新機能の実装や、それらのソリューションを私たちのシステムに統合する際に貴重な支援をしてくれた、 FlashAttention 、 vLLM 、 xFormers 、 Skypilot のメンテナーに感謝します。私たちのモデルがどこでも互換性を持つようにするために、HuggingFace、AWS、GCP、Azure MLの各チームが懸命に支援してくれたことに感謝します。
0%



