ブログに戻る
4分で読めます
ブログ
研究
Mixtral of Experts
2023年12月11日
Mistral AIチーム
Mistral AI は、開発者コミュニティに最高のオープンモデルを届けるという使命を引き続き追求しています。AI の今後には、よく知られたアーキテクチャや学習パラダイムを単に再利用するだけではなく、新しい技術的な転換が必要です。とりわけ重要なのは、コミュニティがオリジナルのモデルから恩恵を受け、新たな発明や利用法を促進できるようにすることです。
本日、チームは、オープンウェイトの高品質な疎(そ)なミクスチャ・オブ・エキスパーツモデル(SMoE)である Mixtral 8x7B をリリースできることを誇りに思います。Apache 2.0 のライセンスのもとで提供されます。Mixtral は、6倍高速な推論によって、ほとんどのベンチマークで Llama 2 70B を上回ります。これは、許容的なライセンスを持つ最も強力なオープンウェイトモデルであり、コスト/性能のトレードオフに関して総合的に最良のモデルです。特に、多くの標準ベンチマークで GPT3.5 に匹敵、または上回ります。
Mixtral には次のような能力があります。
32k トークンのコンテキストを巧みに扱えます。
英語、フランス語、イタリア語、ドイツ語、スペイン語に対応しています。
コード生成において高い性能を示します。
MT-Bench で 8.3 のスコアを達成する命令追従型モデルへと微調整できます。
疎(そ)構造によってオープンモデルの最前線を押し広げる
Mixtral は、疎なミクスチャ・オブ・エキスパーツ(MoE)ネットワークです。フィードフォワードブロックが、8 つの異なるパラメータグループの集合から選び出す、デコーダのみのモデルです。各層において、各トークンに対してルーターネットワークがこれらのグループのうち 2 つ(「エキスパート」)を選択し、そのトークンを処理させ、出力を加算的に組み合わせます。
この手法は、モデルがトークンごとに総パラメータ集合の一部のみを使用するため、コストとレイテンシを抑えつつ、モデルのパラメータ数を増やします。具体的には、Mixtral は合計 46.7B のパラメータを持ちながら、トークンごとに使用するのは 12.9B のパラメータだけです。したがって、入力の処理と出力生成の速度、そしてコストは 12.9B モデルと同等です。
Mixtral はオープン Web から抽出したデータで事前学習されています。私たちはエキスパートとルーターを同時に学習します。
性能
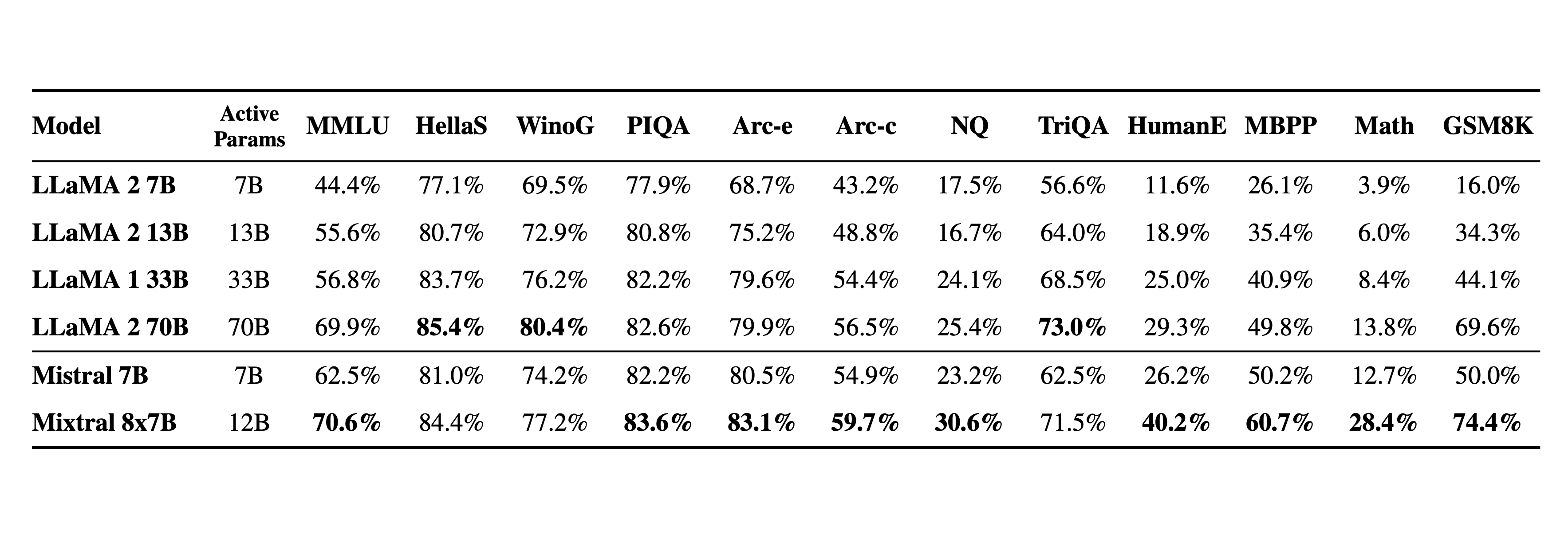
私たちは Mixtral を Llama 2 ファミリーおよび GPT3.5 ベースモデルと比較します。ほとんどのベンチマークにおいて、Mixtral は Llama 2 70B と同等かそれ以上、また GPT3.5 も上回ります。
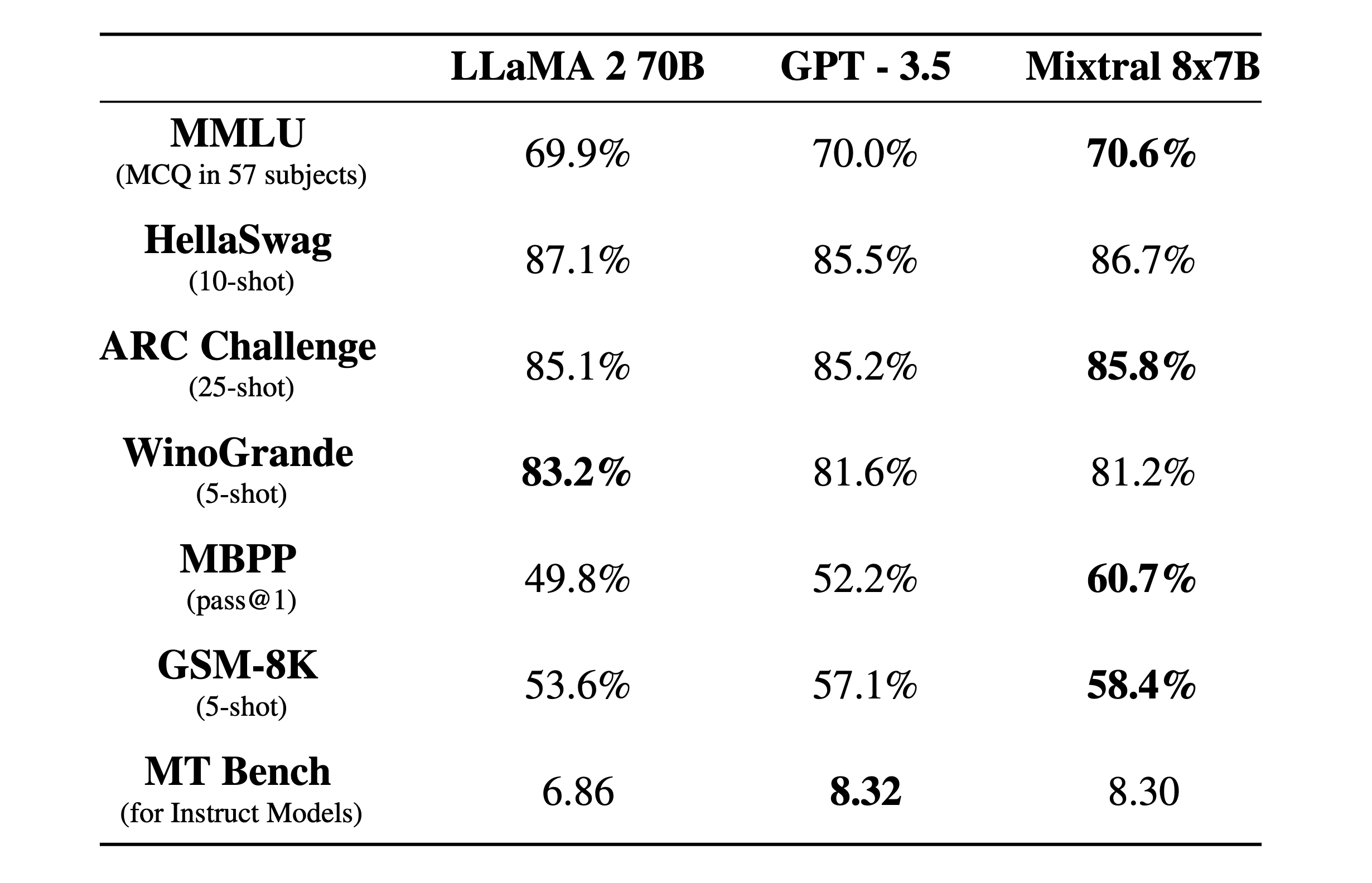
次の図では、推論に使う予算(inference budget)とのトレードオフにおける品質を測定しています。Mistral 7B と Mixtral 8x7B は、Llama 2 モデルと比べて非常に効率的なモデルファミリーに属します。
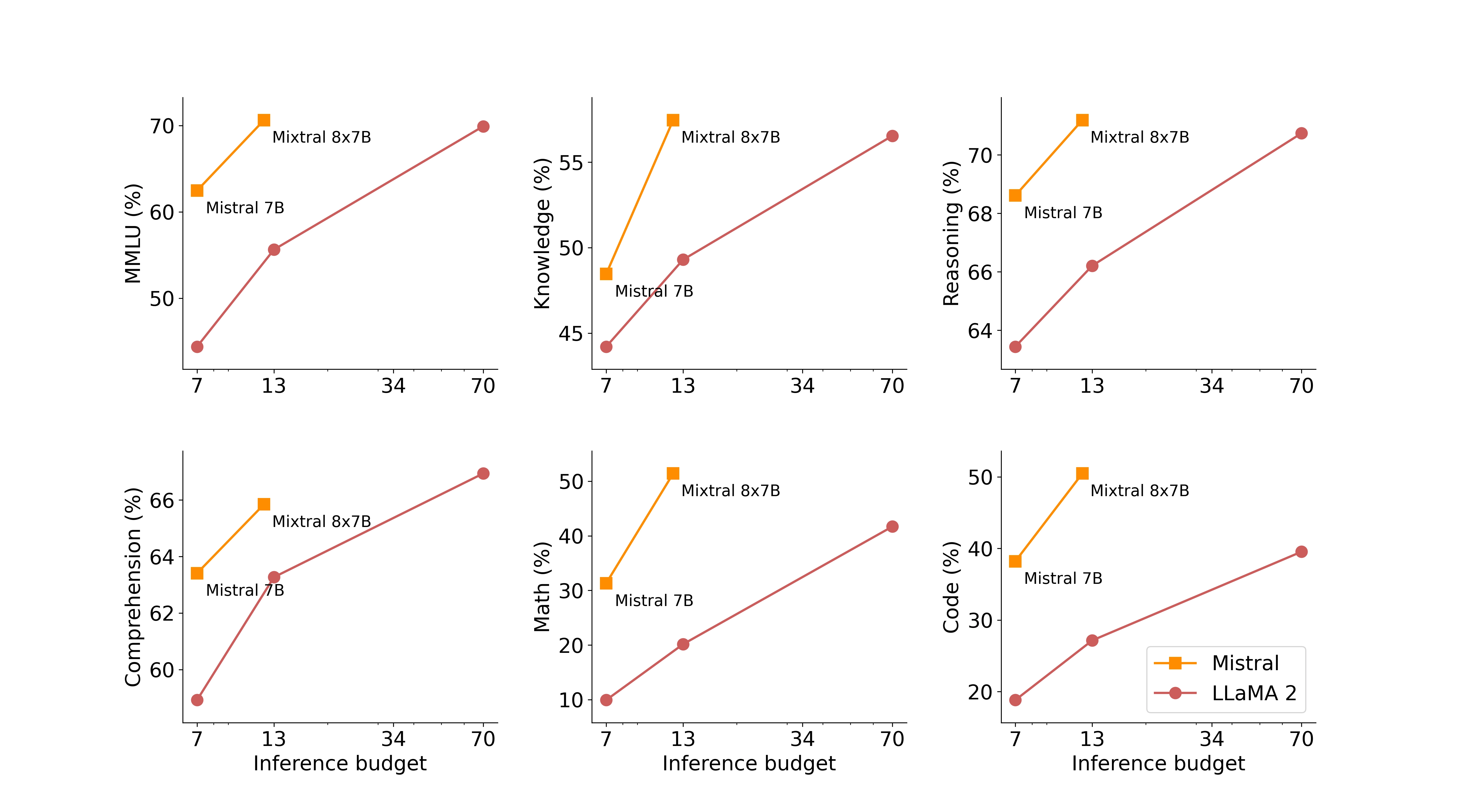
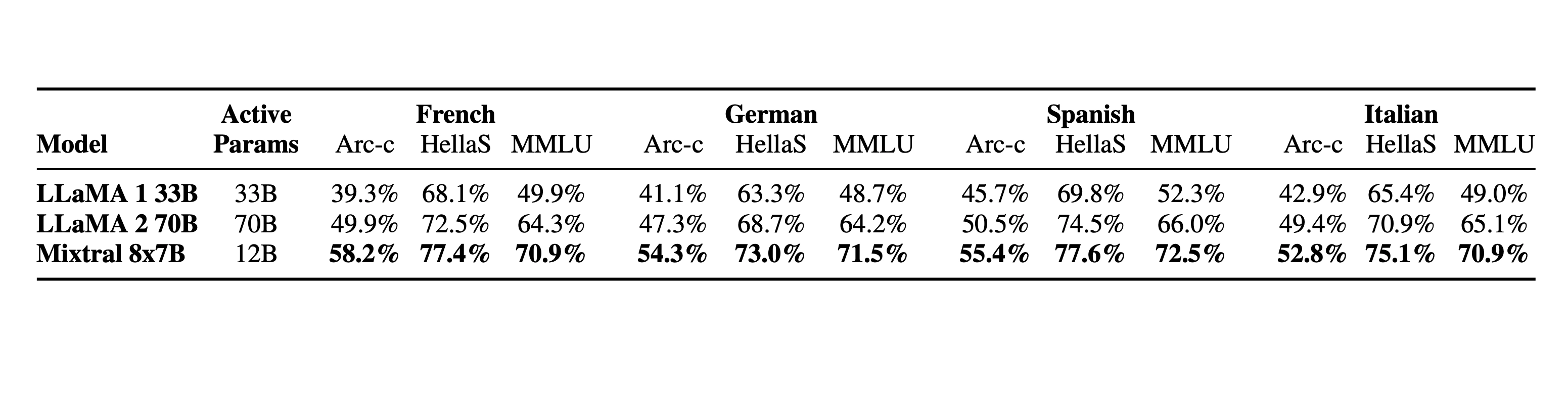
次の表は、上の図に関する詳細な結果を示しています。
幻覚とバイアス。 微調整/嗜好モデリングによって修正可能な潜在的欠陥を特定するために、BBQ/BOLD における ベース モデルの性能を測定します。
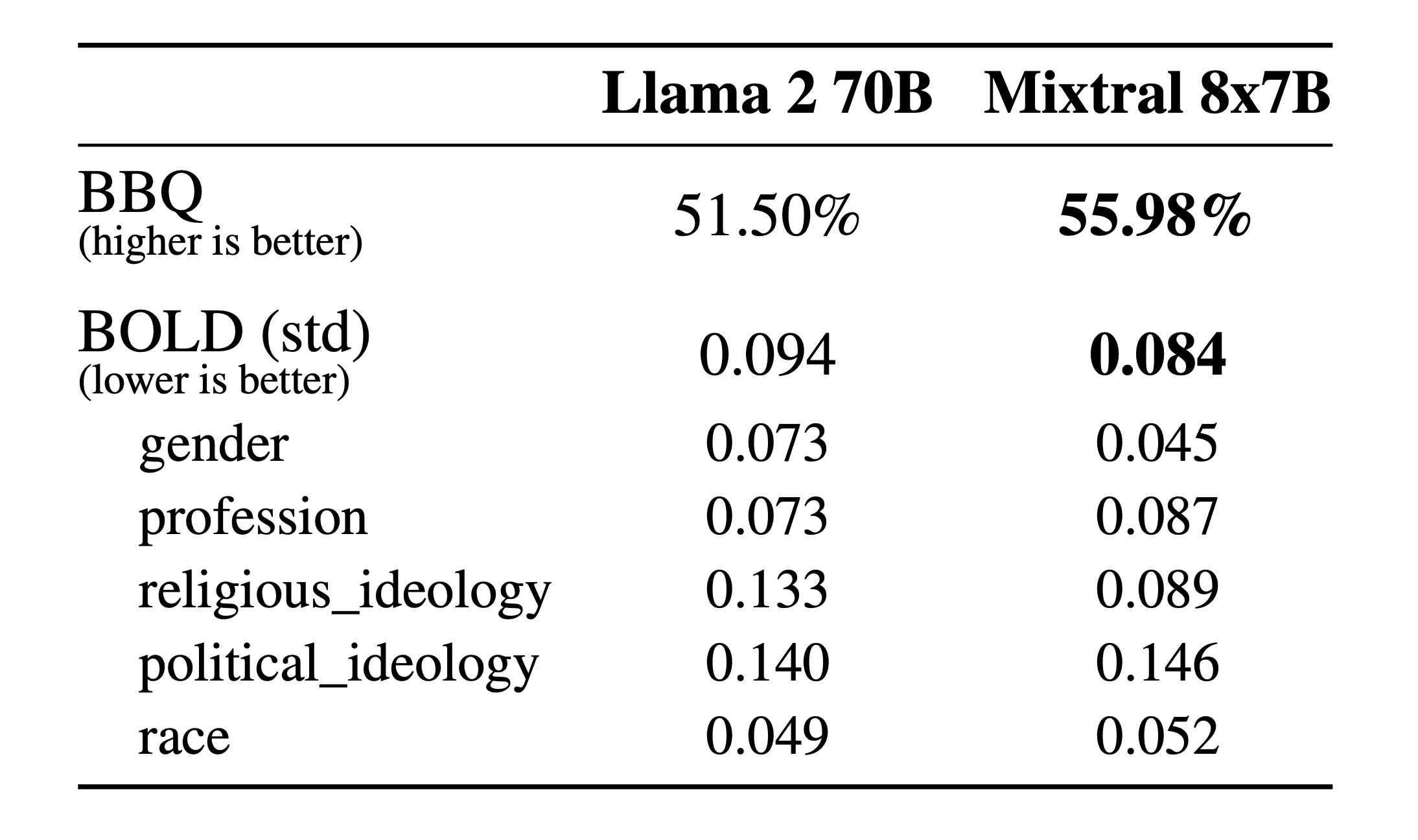
Llama 2 と比べると、Mixtral は BBQ ベンチマークでより少ないバイアスを示します。全体として、Mixtral は BOLD において Llama 2 よりもポジティブな感情表現が多く、各次元内でのばらつきは同程度です。
言語。 Mixtral 8x7B はフランス語、ドイツ語、スペイン語、イタリア語、英語を習得しています。
指示モデル
私たちは Mixtral 8x7B Instruct を Mixtral 8x7B と併せてリリースします。このモデルは、教師あり微調整と、注意深い指示追従のための直接嗜好最適化(DPO)によって最適化されています。MT-Bench では 8.30 のスコアに到達し、GPT3.5 に匹敵する性能を持つ、最良のオープンソースモデルです。
注: Mixtral は、厳格な水準のモデレーションを必要とするアプリケーションを構築する際に、特定の出力を禁止するようにうまくプロンプトできます。これは こちら に例があります。適切な嗜好チューニングも同様の目的に役立ちます。このようなプロンプトがない場合、モデルは与えられた指示にそのまま従うだけであることに留意してください。
オープンソースのデプロイメントスタックで Mixtral を展開する
コミュニティが完全にオープンソースのスタックで Mixtral を実行できるようにするため、効率的な推論のために Megablocks CUDA カーネルを統合する vLLM プロジェクトに変更を提出しました。
Skypilot により、クラウド上の任意のインスタンスで vLLM エンドポイントをデプロイできます。
当社のプラットフォームで Mixtral を利用する。
現在、私たちはエンドポイント mistral-small の背後で Mixtral 8x7B を使用しています。これは ベータ版として提供されています。すべての生成および埋め込みエンドポイントに早期アクセスするには、登録してください。
謝辞
モデルをトレーニングするにあたり、技術サポートをいただいた CoreWeave および Scaleway のチームに感謝します。
0%



