2026年4月27日 - リンクブログ
microsoft/VibeVoice。VibeVoice は、音声認識(speech-to-text)向けの Whisper スタイルのマイクロソフトの音声モデルで、MIT ライセンスで提供され、話者ダイアライゼーションがモデル内に組み込まれています。
Microsoft は 2026 年 1 月 21 日にこれを公開しましたが、今日まで試していませんでした。ここでは uv、mlx-audio(Prince Canuma による)と、17.3GB の VibeVoice-ASR モデルを 5.71GB に変換した mlx-community/VibeVoice-ASR-4bit の MLX 版を使って、Mac でこれを動かすためのワンライナーを示します。なお今回は、最近の Lenny Rachitsky とのポッドキャスト出演のダウンロード版(mp3)に対して実行しました。
uv run --with mlx-audio mlx_audio.stt.generate \
--model mlx-community/VibeVoice-ASR-4bit \
--audio lenny.mp3 --output-path lenny \
--format json --verbose --max-tokens 32768
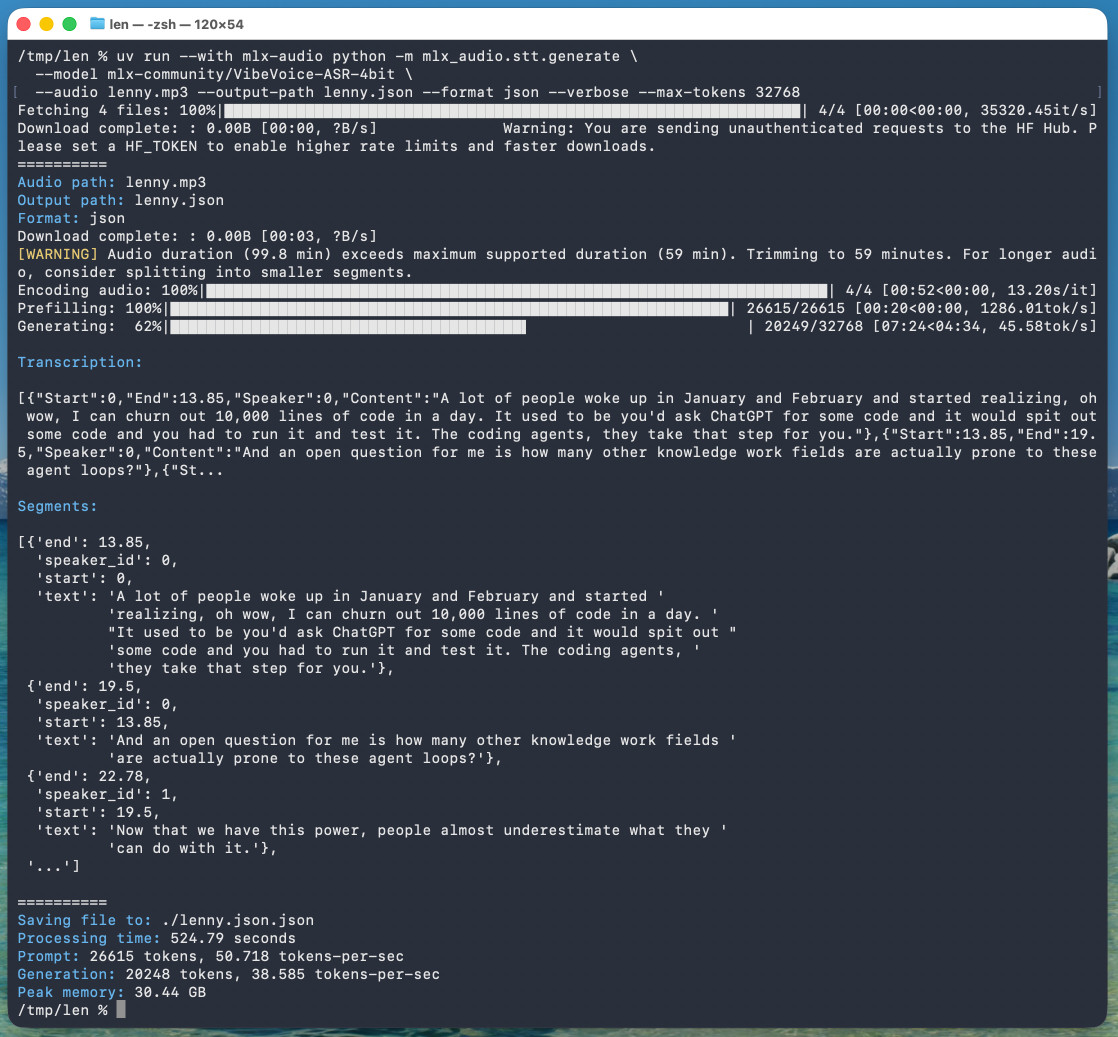
ツールは次を返しました:
Processing time: 524.79 seconds
Prompt: 26615 tokens, 50.718 tokens-per-sec
Generation: 20248 tokens, 38.585 tokens-per-sec
Peak memory: 30.44 GB
つまり、1時間分の音声に対して 8分45秒です(128GB の M5 Max MacBook Pro 上で実行)。
.wav と .mp3 のファイルでも試しましたが、どちらも問題なく動作しました。
--max-tokens を省略するとデフォルトは 8192 で、これは約 25 分分の音声に十分です。試行錯誤の結果それを見つけ、念のため満額の 1 時間分を確実に取れるように 4 倍にしました。
このコマンドはピーク時に 30.44GB の RAM を使用したと報告していましたが、Activity Monitor ではプリフィル段階で 61.5GB、生成段階では約 18GB の使用量を確認しました。
以下が生成された JSONです。キーとなる構造は次のようになっています:
{
"text": "そして私にとっての未解決の問いは、他にもどれだけの知識労働分野が実際にこうしたエージェントループに陥りやすいのか、ということです。",
"start": 13.85,
"end": 19.5,
"duration": 5.65,
"speaker_id": 0
},
{
"text": "この力を手にした今、人は人々がそこから何ができるかを、ほとんど過小評価しています。",
"start": 19.5,
"end": 22.78,
"duration": 3.280000000000001,
"speaker_id": 1
},
{
"text": "今日、私が出しているコードのたぶん 95% は、私自身が手で打ち込んだものではありません。携帯で自分のコードの多くを書いています。信じられないですね。",
"start": 22.78,
"end": 30.0,
"duration": 7.219999999999999,
"speaker_id": 0
}
これはオブジェクトの配列なので、Datasette Lite で開くことができます。そうするとブラウズしやすくなります。
おもしろいことに、この Datasette Lite の表示では 3 人の話者がいます。会話については Lenny と私を識別し、その後、追加のイントロとスポンサー読みで使った音声のために、別の Lenny がいるのです!
VibeVoice は最大 1 時間分の音声までしか扱えないため、上のコマンドを実行するとポッドキャストの最初の 1 時間だけが文字起こしされます。1 時間を超える分を文字起こしするには、音声を分割する必要があり、理想的には分割点で単語が途中までしか文字起こしされないことによるエラーを避けられるように、1 分ほどの重複を入れておくとよいでしょう。その上で、複数のセグメントにまたがって識別された話者 ID を揃える必要もあります。
最近の記事
- すでに亡くなった OpenAI Microsoft AGI 条項の歴史を追う - 2026年4月27日
- DeepSeek V4 - フロンティアのかなり手前、価格はその一部 - 2026年4月24日
- LiteParse for the web でブラウザから PDF テキストを抽出する - 2026年4月23日
これは Simon Willison による リンク投稿で、2026年4月27日 に投稿されました。
microsoft 129 python 1246 datasette-lite 20 uv 93 mlx 43 prince-canuma 8 speech-to-text 18月次ブリーフィング
$10/月 でスポンサーになって、今月の最も重要な LLM の動向を厳選したメールのダイジェストを受け取ってください。
あなたに代わって私が送るので、あなたは読む量が減ります!
スポンサーになる & 購読する



