ブログへ戻る
3分で読めます
ブログ
調査
より安く、より良く、より速く、より強く
2024年4月17日
Mistral AIチーム
Mixtral 8x22Bは、私たちの最新のオープンモデルです。AIコミュニティにおいて、性能と効率の新たな基準を打ち立てます。これは、総141Bのうちアクティブなパラメータは39Bのみを使用するスパース・Mixture-of-Experts(SMoE)モデルで、そのサイズに対して比類のないコスト効率を提供します。
Mixtral 8x22Bには、以下の強みがあります。
英語、フランス語、イタリア語、ドイツ語、スペイン語に堪能
数学とコーディングに強い能力を持つ
ネイティブに関数呼び出しに対応しています。さらにla Plateformeで実装された制約付き出力モードと組み合わせることで、アプリケーション開発やテックスタックのモダナイゼーションを大規模に実現できます
64Kトークンのコンテキストウィンドウにより、大規模ドキュメントから正確に情報を想起できます
真にオープン
私たちは、AIにおけるイノベーションと協力を促進するために、オープン性と幅広い配布の力を信じています。
そのため、Mixtral 8x22Bを、最も寛容なオープンソース・ライセンスであるApache 2.0で公開します。これにより、誰でも制限なしに、どこでもモデルを利用できます。
最高の効率
私たちは、それぞれのサイズに対して比類のないコスト効率を提供するモデルを構築し、コミュニティが提供するモデル群の中で最良の性能対コスト比を実現します。
Mixtral 8x22Bは、私たちのオープンモデルファミリーの自然な延長です。スパースな活性化パターンにより、どの高密度70Bモデルよりも高速である一方、他のどのオープンウェイトモデル(許容的または制限的ライセンスのもとで配布)よりも高い能力を備えています。ベースモデルが利用可能であることは、ファインチューニングのユースケースにとって優れた基盤になります。
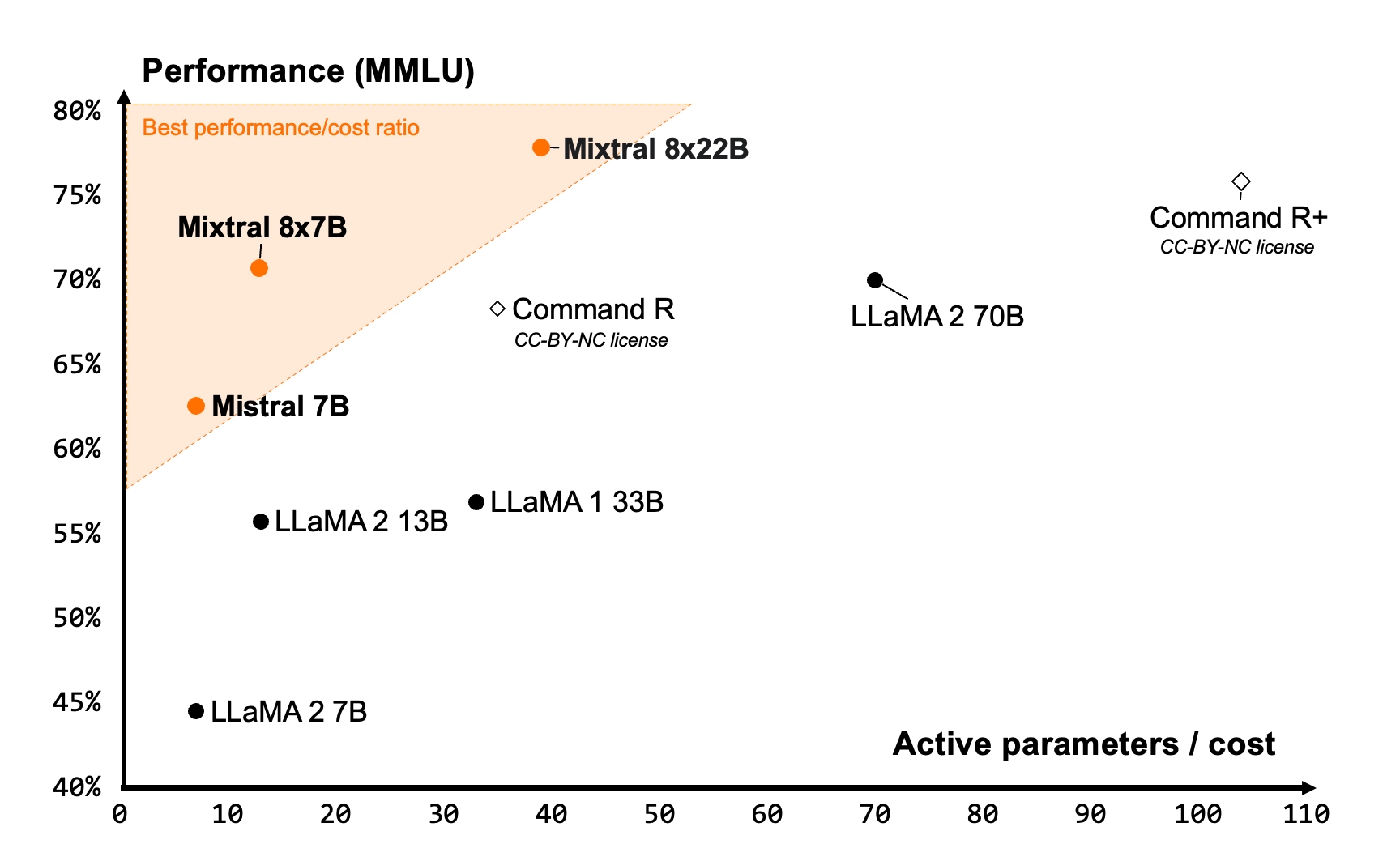
図1:性能(MMLU)と、推論予算のトレードオフ(アクティブなパラメータ数)の関係。Mistral 7B、Mixtral 8x7B、Mixtral 8x22Bはいずれも、他のオープンモデルと比べて高い効率性を持つモデルファミリーに属しています。
比類のないオープン性能
以下は、標準的な業界ベンチマークにおけるオープンモデルの比較です。
推論と知識
Mixtral 8x22Bは推論向けに最適化されています。
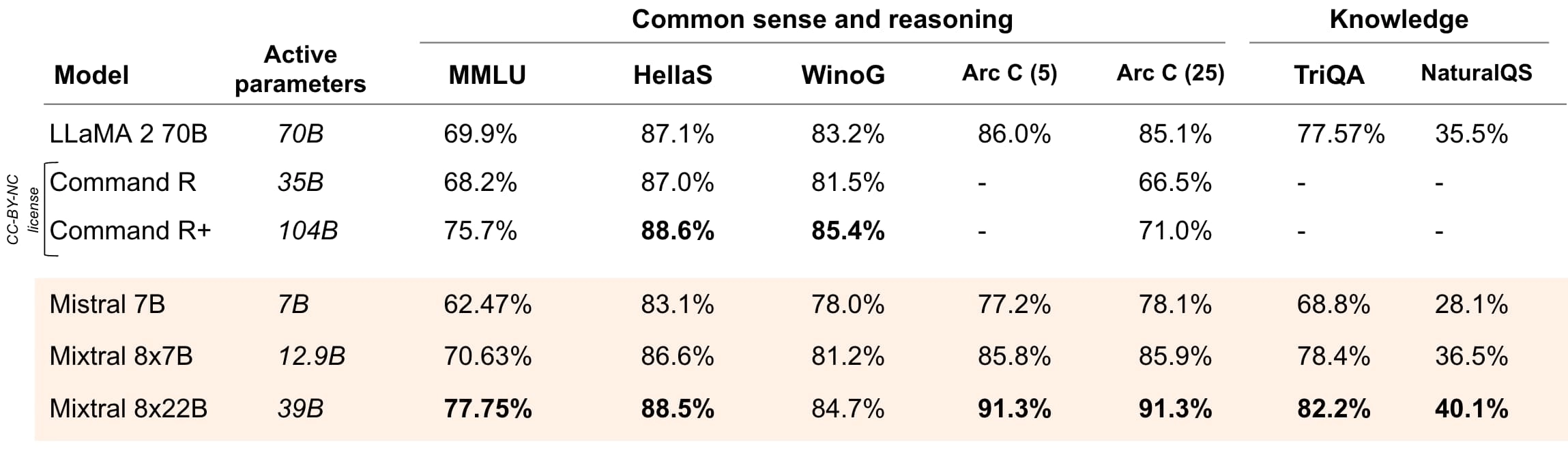
図2:主要なLLMオープンモデル上位陣の、よくある常識、推論、知識ベンチマークでの性能。MMLU(理解における大規模マルチタスク言語の測定)、HellaSwag(10-shot)、Wino Grande(5-shot)、Arc Challenge(5-shot)、Arc Challenge(25-shot)、TriviaQA(5-shot)、NaturalQS(5-shot)。
多言語対応能力
Mixtral 8x22Bはネイティブな多言語対応能力を備えています。フランス語、ドイツ語、スペイン語、イタリア語におけるHellaSwag、Arc Challenge、MMLUベンチマークで、LLaMA 2 70Bを大きく上回る性能を示します。
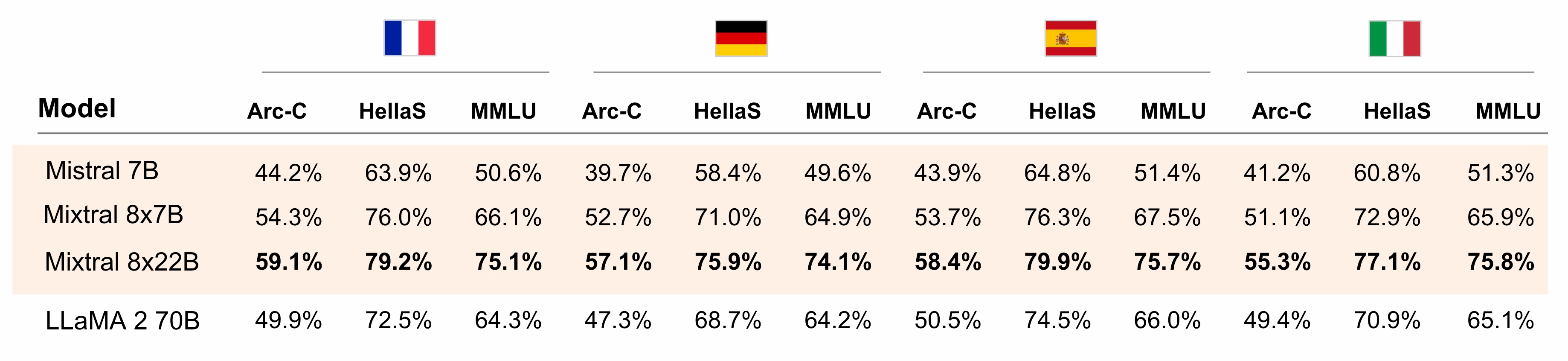
図3:フランス語、ドイツ語、スペイン語、イタリア語における、HellaSwag、Arc Challenge、MMLUでのミストラルのオープンソースモデルとLLaMA 2 70Bの比較。
数学&コーディング
Mixtral 8x22Bは、他のオープンモデルと比べて、コーディングと数学のタスクで最も優れた性能を示します。
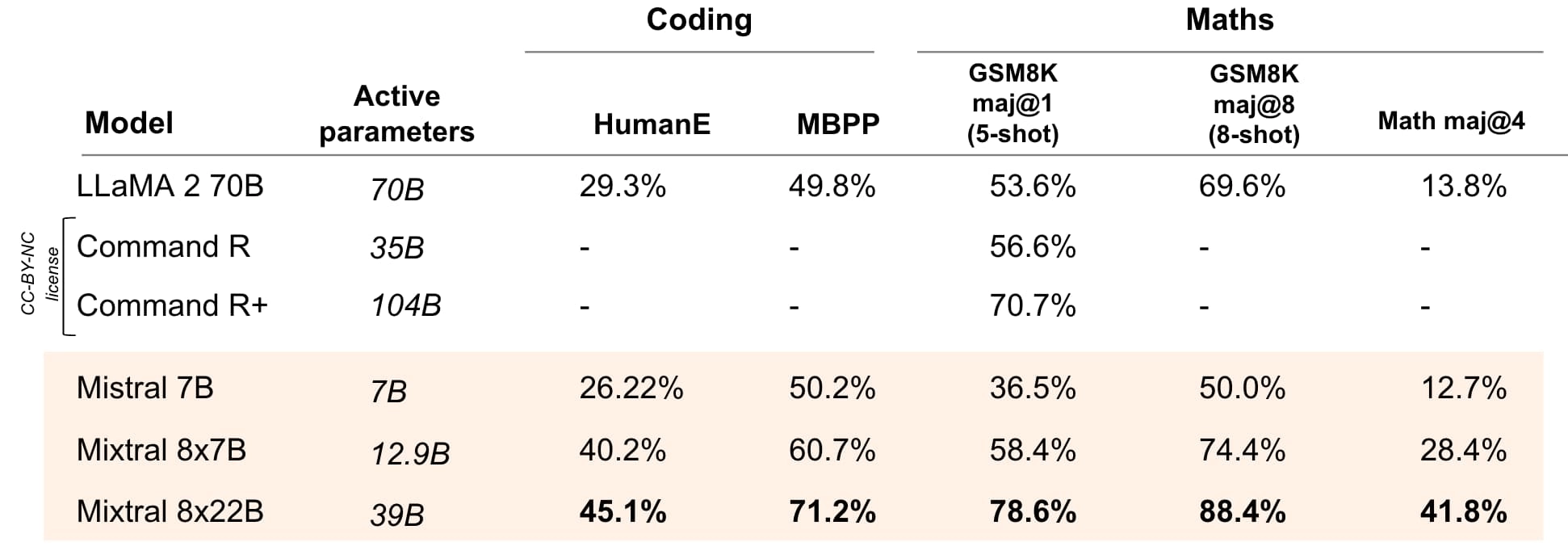
図4:主要なオープンモデルの、人気のコーディングおよび数学ベンチマークにおける性能。HumanEval pass@1、MBPP pass@1、GSM8K maj@1(5-shot)、GSM8K maj@8(8-shot)、Math maj@4。
本日公開されたMixtral 8x22Bの指示(instruct)版は、さらに優れた数学性能を示し、GSM8K maj@8で90.8%、Math maj@4で44.6%のスコアを記録しています。
いまMixtral 8x22Bを la Plateforme でぜひ試してみてください。私たちが共にAIのフロンティアを定義していく中で、開発者コミュニティであるMistralの仲間に加わりましょう。
0%



