中国AIスタートアップMoonshot AI(月之暗面)のKimiチームが発表した論文「Attention Residuals(残差注意機構)」に、Elon Musk(イーロン・マスク)氏が「Impressive work from Kimi」とXで投稿した。世界のAI研究者からもリポストなどが集まり、2026年3月のSNS言及数ランキングで2位に入った。
関連論文: Attention Residuals 関連投稿: https://x.com/elonmusk/status/2033528245464047805Moonshot AIが開発する基盤モデルKimiは、中国発のAIモデルの中でも高い性能で知られる。米NVIDIA(エヌビディア)の年次技術イベント「GTC 2026」にMoonshot AIの楊植麟創業者兼CEO(最高経営責任者)が登壇するなど、世界で存在感を着実に高めている。そのKimiの開発チームが今回、LLM(大規模言語モデル)の根幹設計に正面から切り込んだ。
ほとんど変化がなかった「縦の設計」
2017年にTransformerが登場して以来、基盤モデル開発で研究が進んだのは「横の設計」、つまり系列方向のトークン間Attention(注意機構)の設計だった。Multi-Head AttentionからGrouped Query Attention、DeepSeekのMLA(Multi-head Latent Attention)に至るまで、その進化は目覚ましかった。しかし各層が情報をどう受け渡すかという「縦の設計」、つまり深さ方向の情報統合については、ほぼ手つかずだった。Transformerが層間の情報受け渡しに残差接続(Residual Connection)を採用し、2018年ごろに学習の安定化のためPreNorm構成(層正規化を各層の直前に配置する構成)を適用して以降8年ほど、主要モデルにおいて大きな変化は見られなかった。
Transformerが採用する残差接続とは、直前の層の出力と自身の出力を合算して次の層に入力する仕組みだ。この再帰的な操作は、全ての過去層の出力を「重み1で単純に足し合わせる」ことと等価である。層が深くなるほどこの足し合わせが積み重なるため、隠れ状態の値が増大しやすい。結果として、深い層ほど自身の出力が全体に与える影響が薄れていく。論文が「PreNormの希薄化」と呼ぶこの現象により、大規模モデルの深い層の一部を削っても性能に大きな影響を与えないことが、近年の研究で明らかになっていた。
Attentionを縦方向に適用する
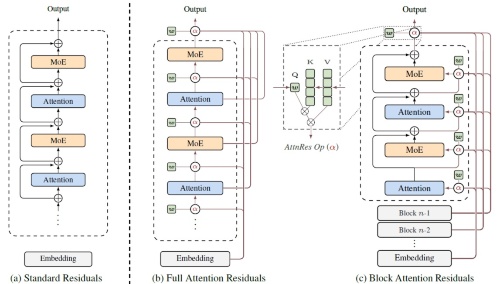
Kimiの提案「Attention Residuals(AttnRes)」の考え方はシンプルだ。横方向のトークン間で機能してきたAttentionを、層と層の間、つまり縦方向にも持ち込む。過去の全ての層の出力を直接参照し、「今どの層の情報が必要か」を動的に選択する。重み1の固定的な足し算から、入力に応じた重み付き選択をするように転換する。
ただし、全層に対して単純にAttentionをかけると、メモリー消費が膨大になってしまう。このため研究チームは、層をブロックに分割し、ブロック単位の代表値に圧縮してから処理する「Block AttnRes」を導入した。この結果、パイプライン並列時の学習オーバーヘッドは4%未満、推論レイテンシー(遅延)の増加は2%未満に抑えた。標準的な残差接続のドロップイン置換として機能するよう設計されているという。
論文によると、総パラメーター480億、活性化パラメーター30億(MoE構成)のKimi Linearで1.4兆トークンを学習したところ、Block AttnResを採用したケースでは、学習で同じ性能に至るまでの計算量を約2割減らせたという。個別ベンチマークでは、多段階推論を要するGPQA-Diamondで7.5ポイント増、数学ベンチマークMATHで3.6ポイント増、コード生成のHumanEvalで3.1ポイント増、全評価タスクでベースラインと同等かそれ以上の結果を示した。他のTransformer系LLMでも同様の効果を再現できるか、引き続き注目を集めそうだ。
次のページ
マルチモーダルAIは本当に「画像を見ているか」、...この記事は有料会員限定です



