2026年4月23日から27日にかけてブラジル・リオデジャネイロで開催された深層学習のトップカンファレンス「ICLR(International Conference on Learning Representations) 2026」。採択論文5357件の中から、注目の論文を紹介する。
ICLR 2026ではOutstanding Paper(優秀賞)として2本の論文が選出された。1本目は「LLMs Get Lost In Multi-Turn Conversation(大規模言語モデルは複数ターンにわたる会話で混乱する)」。LLM(大規模言語モデル)に複数のやり取り(ターン)にわたってプロンプト(指示文)を入力すると、回答能力と信頼度が劣化することを明らかにした。この論文は2026年2月にSNS上でも注目を集めた。AI(人工知能)と会話形式で作業を進める場面が増えるなか、1つ大きな課題を示した。

実証ではひとまとまりのプロンプトを分割(シャーディング)し、指示を少しずつ与えてタスクを解かせた。すると試したすべてのLLMにおいて、1ターンで回答させたときよりも精度が下がることを確認したという。
原因は幾つか考えられるとしている。例えば情報がそろっていないにもかかわらず、モデルが回答の予測を早く立てすぎている可能性がある。あるいは精度の悪い回答予測であっても排除し切れず、モデルが「膨張」している可能性もある。他にも、中間のターンで与えられた情報を軽視したり、冗長に回答しすぎていたり、といった原因が考えられる。
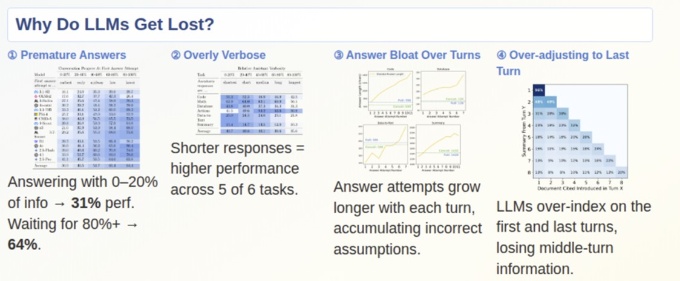
複数ターンでLLMの回答精度が劣化すると考えられる原因
(出所:「LLMs Get Lost In Multi-Turn Conversation」の発表ポスター)
[画像のクリックで拡大表示]
次のページ
筆頭著者である米MicrosoftResearc...この記事は有料会員限定です




