親愛なる皆さん、
シリコンバレーで新しく、話題の多い仕事の1つが、AI Forward Deployed Engineer(FDE)です。これは、クライアント組織の中に組み込まれ、その組織の特定のニーズに合うエージェント型ワークフローの構築や調整など、ソリューションのカスタマイズを支援するエンジニアのことです。OpenAIとAnthropicがFDEをクライアント組織に配置するために new teams を立ち上げて以来、FDEというキャリアパスについて改めて疑問を持っている人たちから話を聞きました。
AIのワークロードに対するFDEの台頭は、AIが新しい仕事を生み出している一つの形です(そして、これからの雇用市場の崩壊というjobpolcalyseの語りが false)という理由でもあります。しかし、以下で説明する通り、AIエンジニアの仕事ははるかに増えると私は考えています。
FDEという役割は約20年前にPalantirによって先駆けられました。Palantirは、政府の拠点にエンジニアを派遣し、安全で外部から隔離されたネットワーク上で業務を行わせました。優れた技術スキルに加えて、FDEにはコミュニケーション能力、場合によってはビジネススキルも必要です。例えば、クライアントと対話してニーズを理解し、プロジェクトに優先順位を付けるための戦略を組み立て、複雑な技術を説明し、クライアントが非現実的な要求をしてきた場合には丁寧に後戻り(押し返す)する必要があります。既製品のLLMを受け取り、それを特定のビジネスニーズに合うカスタムのエージェント型ワークフローへと作り込むために必要な作業量が大きいことから、FDEは再び注目を集めています。
とはいえ、AIエンジニアの仕事の数はもっとはるかに大きくなると私は考えています。企業が自社の組織内に組み込む形で、少数のFDEを受け入れることはあるかもしれません。しかし、ほとんどの企業は、自社の従業員に自社のプロジェクトを進めさせたいと考えるでしょう。私の組織でもFDEを採用していますが、私たちが採用するのはAIエンジニアの方がはるかに多いです。また、よくあるクライアントの懸念として「ベンダーに中立なFDEを見つけるのが難しい」という点があります。というのも、結局のところFDEは、ある特定のベンダーの製品を企業に深く統合するために存在するからです。今は、1年後にどのAIサービスが最適かを予測しにくい局面です。そのため、オプショナリティ(将来、最も適したベンダーを自由に選べること)には非常に大きな価値があります。対照的に、FDEに企業のプロセスを強く結び付けさせてしまうと、オプショナリティは大幅に低下してしまいます。

現時点で私が目にしているのは、LLMプロンプト、エージェント型フレームワーク、evals などのAIソフトウェアコンポーネントを使って、AIによるソフトウェアアプリケーションを構築できるAIエンジニアへの需要が急増していることです。そして、Claude Code、Codex、Antigravity CLI、OpenCodeのようなAIコーディングエージェントを、効果的に使いこなせることが求められています。AIエンジニアの役割が成熟するにつれて、何十年も前に汎用のソフトウェアエンジニア職がフロントエンド、バックエンド、モバイル、データエンジニアリング、DevOps などに細分化していったのと同じように、より専門化された役割へ分裂していくことを私は見込んでいます。
将来、どんな専門化されたAIエンジニアリング職が生まれるのでしょうか?私にはわかりません。たとえば、AI FDE、LLMOpsエンジニア、Evalsエンジニア、AIデータエンジニア、Harnessエンジニア、そしてまだ名前の付いていない他の役割ができるのかもしれません。しかし今のところ私は、価値を大いに生み出すたくさんのAIエンジニアが ゼネラリストとして 活動しているのを多く見ています。スキルのあるAIエンジニアは非常に高い需要があります。私たちの分野が今後10年の間にさらに成熟していくにつれて、AIエンジニアリングの中に新しい専門分野が生まれ、さらに多くの雇用機会につながることを楽しみにしています。
作り続けてください!
Andrew
DEEPLEARNING.AI からのメッセージ DEEPLEARNING.AI

Kian Katanforoosh と Workera による Ambient は、仕事の流れの中であなたのスキルを測定します。すでに睡眠、歩数、ストレスなど、他にも重要なものを測っています。あなたのスキルも測ってみてはどうでしょう? ウェイ トリストに参加する
ニュース
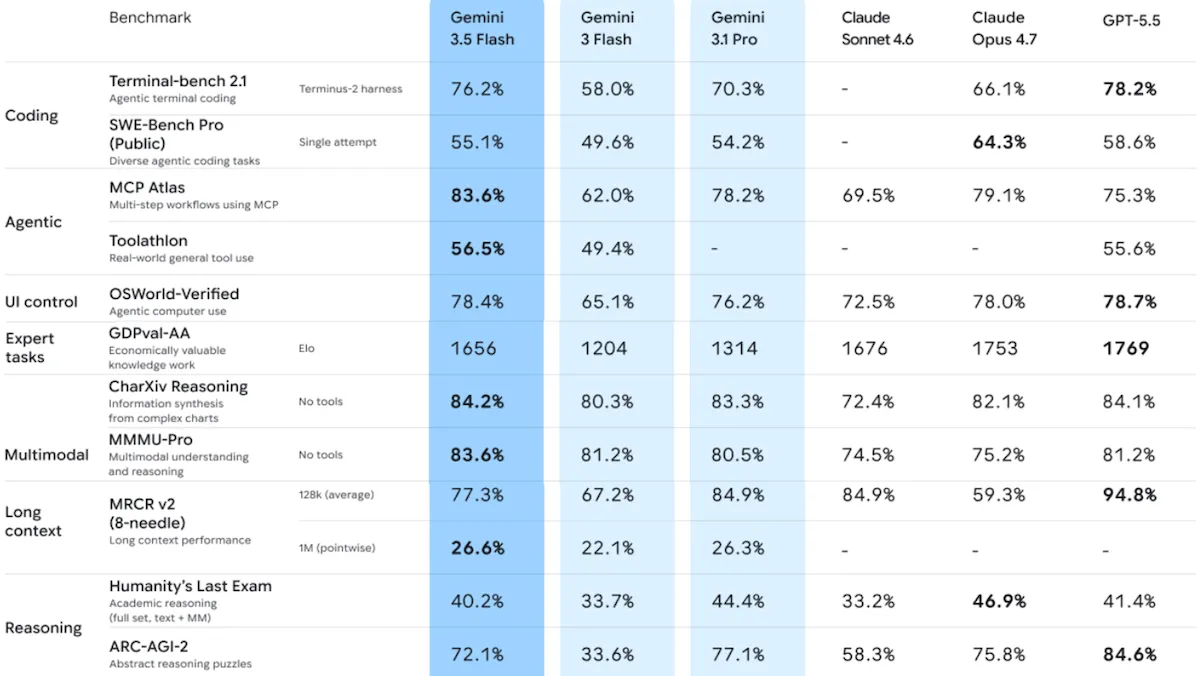
Gemini 3.5 Flash は スピードと スマートさを両立
Google のより高速なモデルは、トークン単価が上昇している流れの一部でもあり、より高い価格帯でありながら実質的な向上をもたらします。
新着情報: Google は Gemini 3.5 Flash をリリース しました。同モデルはミッドティアのマルチモーダルモデルのアップデートです。新バージョンは、エージェント型の能力、視覚理解、そして速度の面で改善を提供しており、価格は先行する Gemini 3 Flash の3倍です。
- 入出力: (最大100万トークンまでの)テキスト、画像、音声、動画を入力し、(最大64,000トークンまでの)テキストを出力(204 tokens per second)
- アーキテクチャ: モノリシック・ではなく複数専門家(Mixture-of-experts)型のトランスフォーマー
- 特徴: 推論レベルの調整(minimal、low、medium、high)、 thought preservation(思考の保持) (推論トークンをコンテキスト内に保持して、多ターン会話をまたいで推論を維持する。Kimi K2.6の preserved thinking 機能に類似)、ツール利用(現時点ではコンピュータ利用は利用不可)
- 性能: Tops Artificial AnalysisのAPEX-Agents-AAベンチマークおよびMMMU-Proマルチモーダル・ベンチマーク Flash。総合的な知能、知識、コーディングにおいて先行する主要モデルに追随する
- 提供/価格: Geminiアプリ、Google AI Studio、Google Antigravity(計算上限の範囲内で、5時間ごとに更新され、週次上限まで)、Google SearchのAIモードで無料。Gemini Enterprise、Gemini Enterprise Agent Platform、APIは入力/キャッシュ済み出力トークンあたり$1.50/$0.15/$9.00(百万トークン当たり)
- 非公開: パラメータ数、学習データおよび手法、アーキテクチャの詳細
仕組み: Googleは、Gemini 3.5 Flashがどのように構築されたかについて、ほとんど詳細を開示していません。
- Gemini 3.5 Flashは「Gemini 3 Flashに基づく」。そしてGemini 3 Flash自体はGemini 3 Proに基づいている、とその モデルカード は述べています。
- これはモノリシックではなく複数専門家(Mixture-of-experts)型のトランスフォーマーで、テキスト、コード、画像、音声、動画について、ウェブからスクレイピングしたものに加えて、ライセンスされた素材、Googleユーザーデータ、合成データを用いてマルチモーダルな事前学習が行われています。
- 複数ステップの推論、多段階での問題解決、定理の証明を扱うデータセットに対して、強化学習による微調整が行われました。
性能: Gemini 3.5 Flashは、マルチモーダル・モデルの1位にごくわずかに届かない位置で動作します。独立したテストによると、エージェントとしての能力と速度の両面で、前モデルに比べて大きな改善が見られ、最先端級の指標も含まれています。Artificial AnalysisのIntelligence Indexでは、推論レベルが異なるさまざまなモデルの条件(レベルは指定なし)で「推論(level unspecified)」に設定されたQwen 3.7 Maxの後ろに位置し、第5位または第7位(推論レベルによる)でした。しかし—Qwen 3.7 Maxを除き—知能スコアがより高いすべてのモデルは、実質的に大幅に遅くなります。
- Artificial Analysisによれば、複数の学術分野にまたがる視覚的推論を測定するMMMU-Proでは、高推論(high reasoning)に設定したGemini 3.5 Flashの正答率は84%で、記録された中で最高でした。2位はGemini 3.1 Pro Preview(82%)です。
- 投資銀行業務、マネジメントコンサルティング、企業法務から抽出した長時間のエージェント課題をテストするAPEX-Agents-AAでは、Gemini 3.5 Flash(正答率47.1%)が初回の試行でトップを獲得し、2位のGPT-5.5(正答率37.7%)に対して約10ポイントの差をつけました。現実世界のエージェント課題であるGDPval-AAでは、高推論(1,656 Elo)に設定したGemini 3.5 Flashが、推論レベルが指定されていないGemini 3.1 Pro Preview(1,314 Elo)を上回り、さらにGPT-5.5のxhigh(1,769 Elo)の後塵に退きました。
- 抽象的な視覚推論のテストであるARC-AGI-2では、高推論に設定したGemini 3.5 Flashは、 ARC Prize leaderboard で72.1%を記録しました。これはGemini 3.1 Pro Preview(77.1%)と、xhigh推論に設定されたGPT-5.5(85.0%)に次ぐ結果です。
- 正答にはポイントを与え、幻覚的な推測にはペナルティを課す知識ベンチマークであるAA-Omniscienceでは、推論(23)に設定したGemini 3.5 Flashは、推論(33)に設定したGemini 3.1 Pro Previewおよび最大推論(26)に設定されたClaude Opus 4.7に後れを取っています。
- 2026年5月24日時点で、Arena.aiのリーダーボード(ブラインドな人間同士の対戦比較でモデルの順位付けを行う)では、Gemini 3.5 FlashがText Arena(1,480 Elo)で 9位 、WebDevのコーディング部門で10位(1,506 Elo)でした。AnthropicのClaude Opus 4.6と4.7はいずれのアリーナでも上位3枠を占めています。Text Arenaのカテゴリ別内訳では、Gemini 3.5 Flashは数学部門で1位(1,521 Elo)でしたが、コーディング部門では31位(1,507 Elo)でした。
ニュースの裏側: Googleは、開発者向けの年次イベントであるGoogle I/O 2026にてGemini 3.5 Flashを発表しました。ここでは、そのイベントからの他のAI関連発表を紹介します:
- Googleは、AIコーディングツールである Antigravity を刷新し、MicrosoftのVSCodeのような人気IDEに似ている点を弱め、エージェントの管理を重視するようにしました。Antigravityのコマンドライン版は、オープンソースのGemini CLIに代わります。
- 同社は、マルチモーダルモデルのファミリーであるOmniを発表しました。最初の提供は Omni Flash で、軽量なモデルとして、テキスト、画像、音声、動画から動画を生成できるほか、これらの入力の任意の組み合わせにも対応します。Omni Flashは、GeminiアプリおよびGoogle Flowを通じて、Google AI Plus、Pro、Ultraの加入者が利用できますが、APIではまだ提供されていません。
- Gemini 3.5 Flashにより、 Google Search は、より会話的でチャットボットのような検索クエリを可能にし、ユーザーに代わってオンライン調査を行うエージェントの動力源となり、またSearchの従来の上位10リンクを、出典を引用してユーザーの質問に答える、よりAI生成の要約へ置き換えられるようになります。
なぜ重要か: Gemini 3.5 Flashは、「Flash」が意味するものを変えます。Gemini Ultra、Pro、Nanoの後に登場した、小型で高速なモデル・ティアとして導入された現在の「Flash」は、HaikuよりもAnthropicのSonnetに近い、Googleのミドルティアのマルチモーダルモデルです。モデルの速度は、複数ターンを要するエージェントを構築する開発者や、チャットボット、検索、画像・動画解析のような低レイテンシー用途のために、生成される追加トークンの価値があるかもしれません。
私たちは考えています: Google は Gemini 3.5 Flashが競合モデルに比べてしばしばコストが半分未満で済むと述べています。しかしArtificial Analysisは、Intelligence Indexでテストを実行したところ、実際にはGemini 3.1 Proよりもコストがかかることが分かったとしています。Flashという呼称は、エージェント型のワークロードを実行する開発者にとって明確なコスト優位をもはや意味しません。Anthropic、OpenAI、Googleは、新しいフラッグシップ製品およびFlashティアのモデルについて、1トークン当たりの価格を引き上げました。Gemini 3.5 Flashも同じパターンに当てはまります。

欧州は一部の AI規制を一時停止
欧州連合(EU)は、画期的なAI法(AI Act)のいくつかの条項を弱め、他の条項については、同法が欧州企業の競争力を低下させると、企業や政策担当者が主張したことを受けて延期しました。
新たに何が起きたか: 欧州議会と加盟国は、 AI法を修正 し、連合が安全、健康、個人の権利に対して重大な脅威をもたらすと考える用途を対象にした制限の一部を延期することなど、他の変更も行うことで合意しました。 修正案 は、EUの理事会と議会による正式採択を待っています。EUは、これらの修正案を「市民と企業の双方にとって、より安全でよりシンプルなルール」と特徴づけました。
仕組み: 修正案は概ね、EUのAIオフィスによる監督および執行の責任の整理を進めます。また、AI開発者が特定の条項に対応するための期限を延長し、他の条項については簡素化します。
- 法執行、重要インフラ、雇用、移住、個人の身元確認などに用いられるものを含め、「高リスク」と見なされるAIシステムの要件は、従来の期限である2026年8月から2027年12月へ延期されます。新しいモデルをテスト中により広い世界から隔離するため、開発者は2027年8日までに、監督されたサンドボックス環境を実装することになります。さらに、機械や玩具などのAI駆動型製品についての期限は2028年8月まで延長され、AIが生成した出力へのウォーターマーキングやその他の透明性に関する要件も、概ね2026年12月まで延びます。
- 改定は、AIシステムの学習および導入において個人データを使える方法を調整します。現行のEU法では、個人データの一部のカテゴリは「厳密に必要な場合」に限って使用できます。改定では、バイアスを検出し軽減するために個人データを使用できるようにします。
- また、一部の製品について例外を設ける、あるいは例外の扱いを明確化します。たとえばAI法は、すでに製品安全法によって規制されている産業用機械には影響しません。さらに、より軽いコンプライアンス要件や行政負担は、一部の小規模企業(年間の全世界売上が1,000万ユーロ以下、または総資産が1,000万ユーロ以下のいずれかで、従業員数が50人未満)や「小型ミッドキャップ」企業(年間の全世界売上が1億5,000万ユーロ以下、または総資産が1億2,900万ユーロ以下のいずれかで、従業員数が概ね250〜749人の企業)に対して、場合によって適用されます。
- 修正案は、注目すべき1つの領域でAI法を強化します。すなわち、子どもの性的に露骨な画像や、同意のない実在の人物のヌード画像の生成を禁止します。
ニュースの背景: 2024年、EU は AIを規制するための、世界でもっとも厳格な法律を可決しました。この法律は同年中に施行され、一部の条項はその後の数年かけて段階的に適用されることになりました。立法プロセスが始まった時点から、安全性を実質的に改善することなく過度な負担を課すものだとして批判されました。
- 2023年には、163社の幹部が書簡に署名し、 同法案を 「官僚的だ」と主張しました。2025年には、110社が、規制が「不明確で、重複しており、ますます複雑になっている」ためとして、規制の実施スケジュールの延期を政策担当者に 求めました 。シーメンスやSAPなど、ドイツの産業・ソフトウェア企業は、規制によって前進が阻まれているとして、改定を ロビー活動 し、訴えていました。
- 2つの初期報告が、修正案に影響を与えました。イタリアの元首相エンリコ・レッタによって、2024年4月に 報告書 が発表され、EUは27の国の市場に分断されていて、欧州企業が米国や中国の企業のように規模を拡大(スケール)できなくしていると主張しました。2024年9月の 報告書 では、欧州の競争力に関する観点から、地域の停滞するGDP成長を「存亡をかけた課題」と位置づけ、イノベーション・ギャップの解消、脱炭素化、依存の低減に焦点を当てました。
- 2025年初め、EUの執行機関である欧州委員会は 規制上の負担を減らし、ルールを簡素化し、経済の競争力を高める ことを目的とする意向を発表しました。
- 2026年2月、欧州委員会は 提案していたAI責任指令 を撤回しました。物議を醸していた提案法であり、AI法(AI Act)とは別に、AIによる害に関する訴訟についてEU全域の基準を導入するはずでした。
世間の反応: 改正案への即時の反応は賛否が分かれました。AI業界は概ね、追加された柔軟性を歓迎する一方で、消費者団体は、安全基準が弱まる可能性について懸念を表明しました。いくつかの報道は、それらを、ビジネス上の利益をなだめるために法律を骨抜きにするものだと位置づけました。欧州消費者機構(BEUC) は 、この取引によってデジタル環境がより安全でなくなり、AI企業にとって危険な抜け穴が生まれると述べました。
なぜ重要か: AI法は、その当初の形でも更新後の形でも、「AIによる『システム上のリスク(systemic risks)』」を軽減することを目的としています。この概念は、金融やインフラの規制から借用されたもので、産業全体や経済の大部分に波及しうる失敗を指します。AIがシステム上のリスクをもたらすという考えは、現時点では推測の域を出ません。一方で、過剰な規制は、イノベーションを萎縮させ、有益な技術の導入を阻むという経済的リスクを招きます。今回の改正は、開発者への負担を緩和し、企業に対して要件を理解し順守するための余裕(スケジュール面の猶予)を追加で与え、製造業や半導体などの重要分野における継続的なイノベーションへの道を切り開くことで、リスクと便益のバランスを取ることを狙っています。
考えるべき点: 当初のAI法の多くの条項は 不明確 で、範囲が広すぎる、または不必要に負担が大きいものでした。今回の改正は、有益な要素を維持しつつ、法律をより負担の少ないものにするためのように見えます。これは、欧州の競争力にとって良い一歩です。
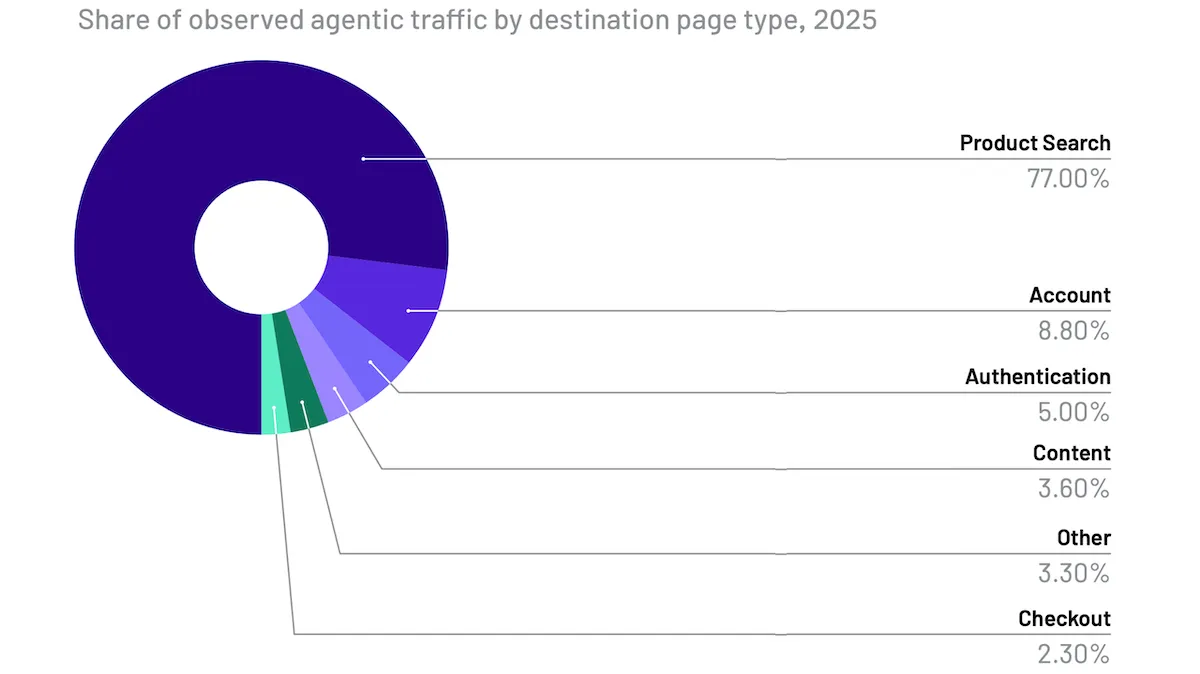
AIが書いたウェブをエージェントが巡る
昨年、インターネット上でのAI主導の活動が急増したことを示す調査結果が出ました。
何が起きたか: AI主導のトラフィック(AIシステムによって、またはそのために生成されたインターネット上のやり取り)は、サイバーセキュリティ企業Human Securityによる レポート によれば、2025年にほぼ3倍に増えました。AIシステムやボットを訓練するために大量のデータを収集したクローラ、および即時利用のために価格などのデータポイントをスクレイピングしたボットの量は、いずれも一桁台の伸びを示しました。AIエージェントやエージェント型ブラウザによるトラフィックは急増しました(ただし全体に占める割合は依然としてごくわずかでした)。AI主導のトラフィックの95%以上は、著者らが「小売・EC(retailing and ecommerce)」「ストリーミングおよびメディア」または「旅行・ホスピタリティ(travel and hospitality)」として指定した活動でした。
仕組み: この 「2026 State of AI Traffic and Cyberthreat Benchmark Report」 は、Human Securityが2025年に観測した1京(quadrillion)超のインターネット上のやり取りの分析に基づいています。Human Securityは200カ国・地域以上で約1,200社の顧客にサービスを提供しています。
- AI主導のトラフィックはほぼ3倍になった一方、自動化トラフィック(AI主導および従来型のボットによるトラフィックを含む)は23%以上増加しました。人間によるトラフィックは約3%増えました。
- AI主導のトラフィックの増加には、訓練データを収集するクローラ(年間のAI主導トラフィックの68%で、前年の2倍超の量)、即時利用のためのデータを収集するスクレイパ(年間で32%で、量は7倍の増加)、ブラウザ風のタスクを実行するエージェント(12月時点で1.7%、前年同月比で約80倍の成長)などが含まれます。
- エージェント型のやり取りのうち77%は、商品ページおよび検索ページで発生しました。残りは、アカウントページ、認証、そして取引の完了の順でした。
- OpenAIは、自動化トラフィックの約69%を担っていました。これには、ChatGPTのユーザーと訓練データを収集するクローラ(OAI-SearchBot)およびタイムリーな情報(GPTBot)が含まれます。Metaは16%で、Anthropicは約11%でした。
セキュリティ上の含意: 研究者らは、相当量の自動化トラフィックが悪意のあるものだと判断しました。
- 研究者らが悪意があると見なしたスクレイピング活動は、AI主導のやり取りを助けるのではなく、競争インテリジェンスや体系的な値下げといった目的のためにデータを抽出することを狙っており、前年からほぼ47%増加しました。(研究者らは、スクレイパが自己の身元を偽装した、認識された攻撃パターンに従った、またはその他の点で疑わしい振る舞いをした場合に、トラフィックを悪意があるものとラベル付けしました。)研究者らが特定した脅威プロファイル75万件のうち、60%以上が悪意のあるスクレイピングに関与していました。
- ボットがユーザーアカウントを乗っ取ろうとする攻撃は、年を通じて30%以上減少しました。しかし残った試みには、アカウントにログインされた後に発生した攻撃が4倍に増えたことが示されています。こうした攻撃は、盗まれた認証情報や進行中の乗っ取られたセッションを通じて既存アカウントを悪用することが多い一方で、エージェントが新たにアカウントを作成したケースは前年から89%増加しました。
- 侵害された決済カードを含む取引トラフィックの割合は「低く安定」していましたが、カード発行元によってブロックされた量は20%増加しました。これは、インターネット上で実行される取引の件数が増えていること、エージェントがカード番号を切り替える能力が高まっていること、あるいはその両方を反映している可能性があります。
はい、ただし: このレポートは、人間のセキュリティ(Human Security)のプラットフォーム上での活動だけを分析しており、インターネット全体ではありません。さらに、悪意のある通信はしばしば出どころを偽装するため、研究者が特定のデータ点を評価する際に誤りが生じる可能性があります。
なぜ重要か: 自律型システムがインターネットを、追加のトラフィックの波で押し流しており、今後もこの傾向が当面の将来にわたって続く可能性が高いです。これを見据えて、インフラは新たに構築するか、アップグレードしていく必要があります。また、自動化された活動の増加はサイバーセキュリティ上の課題も引き起こします。というのも、正当なAIエージェントも、以前は悪性ボットのシグナルだったのと多く同じ活動 — 製品の閲覧、アカウントの作成、取引の確認(チェックアウト) — を行うためです。
私たちはこう考えています: インターネット上のエージェント型トラフィックは、いままさに始まったばかりです。昨年の80倍の増加は、エージェントがより能力を持ち、頑健で、信頼できるようになっていくにつれて、今後数年でさらに加速していくはずです。
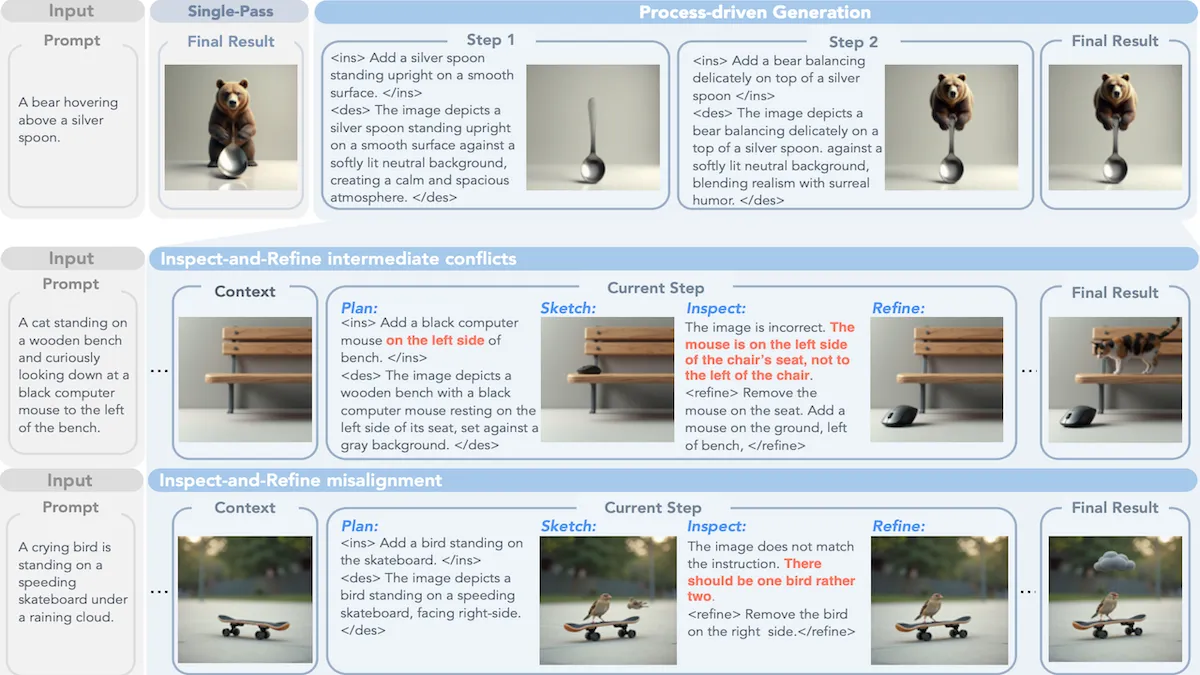
段階的に生成された画像を計画する
拡散(diffusion)やフローマッチングを使うテキストから画像への生成器は、通常は一度に1枚まるごとの画像を合成します(ただし、全体の画像を段階的に改良します)。研究者は、画像の合成を離散的な段階に分割し、その途中結果を確認して修正することで、より良い結果を得ました。
新しい点: Lei ZhangらはMeta、カリフォルニア大学サンディエゴ校、ウースター工科大学、ノースウェスタン大学の共同研究者とともに、画像生成器のための微調整 方法 を提案しました。この方法は、計画によって画像を合成するようにモデルを学習させます。具体的には、要素を生成し、それがプロンプトに合っているかを確認し、必要なら修正し、さらに別の要素を生成する — といった流れを繰り返します。
重要な洞察: テキストから画像へのモデルはしばしば 失敗 して、空間関係(例えば、ある要素が別の要素の上、下、前、後のどれにあるか)や、物体の属性(例えば、指・腕・脚の数など)を表現できないことがあります。モデルが、段階的なプロセスをループさせながら画像を完成させることを学ぶと、生成プロセスをより制御しやすくなります。例えば「銀のスプーンの上に浮かぶクマ」のようなプロンプトが与えられた場合、段階は次のようになります:
- 計画(Plan)。 次に行う変更のための指示を書く(反復1:「クマを描く」;反復2:「クマの下にスプーンを追加する」;など)そして、変更後の画像の説明を記述します。
- スケッチ(Sketch)。 ここまでの画像の更新版を生成する(反復1:クマの画像;反復2:クマとスプーン)。
- 検査(Inspect)。 指示と説明をプロンプトと照合し、画像を指示と照合します。
- 洗練(Refine)。 必要ならそれを直すための命令を出す(反復2:「スプーンはクマの前にあったので、クマの下に描いて」)そして、新しい画像を生成します。
このプロセスを表すデータで学習することで、モデルは、プロンプトに基づいて画像を生成するだけでなく、画像の合成を組み立て、それを修正することも学べます。
仕組み: 著者らは BAGEL-7B、事前学習済みのマルチモーダルモデルから始めました。このモデルは画像とテキスト(たとえば、2枚の画像とそれらを合成するための指示)を受け取り、画像とテキスト(たとえば、合成された画像と、入力画像がどう変えられたかの説明)を生成します。著者らは、計画・スケッチ・検査・洗練の段階を切り替えながら合成を行うことで画像を生成するように、このモデルを微調整しました。
- 計画とスケッチのための微調整: 計画およびスケッチ段階の微調整用データセットを作るために、著者らは32,000件の例を生成しました。各例には、約3〜5枚の中間画像と最終画像が含まれます。これは、 GPT-4oに two datasets のプロンプトをテキストベースのシーングラフへ変換させることで行いました。グラフのノードはオブジェクト(たとえば「cat」「bear」)またはオブジェクトの属性(例:「furry」)であり、エッジはそれらの関係をエンコードしていました(例:猫が「is」furry)。各グラフから、オブジェクト・属性・関係を含む部分をランダムに選びました。そしてGPT-4oに、それらの部分を使って、それらのオブジェクト、属性、関係を画像に追加するための段階的な(incremental)プロンプトへ変換するよう依頼しました。段階的な変更ごとに、 FLUX.1 Kontext を用いて画像を生成し、GPT-4oが段階的プロンプトと整合すると判断した結果のみを残しました。著者らはモデルをテキスト画像の例で微調整しました。モデルは(i)例の次のテキストトークンを生成すること、そして(ii)いくつかのフローマッチング手順を通じて、現在の画像の画素値を調整することで次の画像を生成すること、を学びました。
- 検査のための微調整: 検査段階の微調整用データセットを作るために、著者らは計画とスケッチの微調整後のモデルを使用しました。まず、段階的な指示と画像の例を生成し、その後GPT-4oに、中間テキストの説明が元のプロンプトと矛盾しているかどうかを判定させました。最後に、GPT-4oに批評(critique)と修正指示を生成させました。著者らは、元のプロンプトと整合している例をほぼ7,000件、整合していない例をほぼ8,300件作成しました。GPT-4oの批評と指示を再現することを学ぶことで、モデルは、現在の計画を元のプロンプトと整合すると受け入れるのか、あるいは矛盾をどう直すかを説明するのかを学習しました。
- 洗練のための微調整: 著者らは、 dataset として、画像、それをどう改善できるかに関するテキストの反映(reflection)、そして改善後の画像を用いてモデルを微調整しました。
- 最後に、同じ損失項を以前と同様に用いて、3つすべてのデータセットをまとめてモデルを微調整しました。
結果: 著者らの微調整手法は、テキストプロンプトに合う物体同士の関係を生成画像で再現する必要があるタスク(たとえば、スプーンの後ろにクマを置くのではなくスプーンの上にクマを置く)で、BAGEL-7Bの性能を向上させました。また、特定の時間帯や歴史的な時代の場面のような、現実世界の知識に基づいて画像を生成する能力もBAGEL-7Bで改善しました。
- プロンプトに書かれた詳細のうち、生成された画像に実際に現れる割合を測定するGenEvalでは、著者らの手法により、62,000件の例で微調整した後にBAGEL-7Bが77%から83%へと向上しました。この手法は131のフローマッチングステップを使用しました。対照的に、 PARM は、中間のノイズのある拡散状態を批評することで画像生成を改善する方法で、688,000件の例で微調整した後に77%を達成しました。PARMは1,000のフローマッチングステップを使用しました。
- さらに WISE では、GPT-4oを使って、生成画像の写実性、美的品質、そして生成画像とプロンプト間の整合性(0〜1、値が大きいほど良い)を評価しますが、この手法によりBAGELは平均で0.7から0.76へと向上しました。微調整されたモデルは、シーンを正しい時代や時間的文脈に配置することがより多くなりました。化学データセットでテストすると、化学的にもっともらしい構造、物質、実験室の場面を生成することがより多くなりました。
重要な理由: 画像生成器はしばしば見栄えのよい画像を作りますが、その出力はプロンプトと食い違うことがよくあります。たとえば、物体の位置が不適切だったり、属性が誤っていたりします。本研究は、単に学習データ量を増やすだけではなく、こうしたシステムをより信頼できるものにするための方法を提供します。
考えてみると: 画像ジェネレータが段階的に画像を構成することは、入力に対して段階的に推論するLLMに 類似しています。どちらのアプローチも、モデルに対して要求を部品に分解させ、そしてどちらも出力を改善します。



